


{kind=link}
En el panorama en rápida evolución de IA generativa (GenAI), los científicos de datos y los creadores de IA buscan constantemente herramientas poderosas para crear aplicaciones innovadoras utilizando modelos de lenguaje grande (LLM). DataRobot ha introducido un conjunto de métricas avanzadas de evaluación, pruebas y evaluación de LLM en su Playground, que ofrece capacidades únicas que lo diferencian de otras plataformas.
Estas métricas, que incluyen fidelidad, corrección, citas, Rouge-1, costo y latencia, brindan un enfoque integral y estandarizado para validar la calidad y el rendimiento de las aplicaciones GenAI. Al aprovechar estas métricas, los clientes y los creadores de IA pueden desarrollar soluciones GenAI confiables, eficientes y de alto valor con mayor confianza, acelerando su tiempo de comercialización y obteniendo una ventaja competitiva. En esta publicación de weblog, profundizaremos en estas métricas y exploraremos cómo pueden ayudarlo a desbloquear todo el potencial de los LLM dentro de la plataforma DataRobot.
Explorando métricas de evaluación integrales
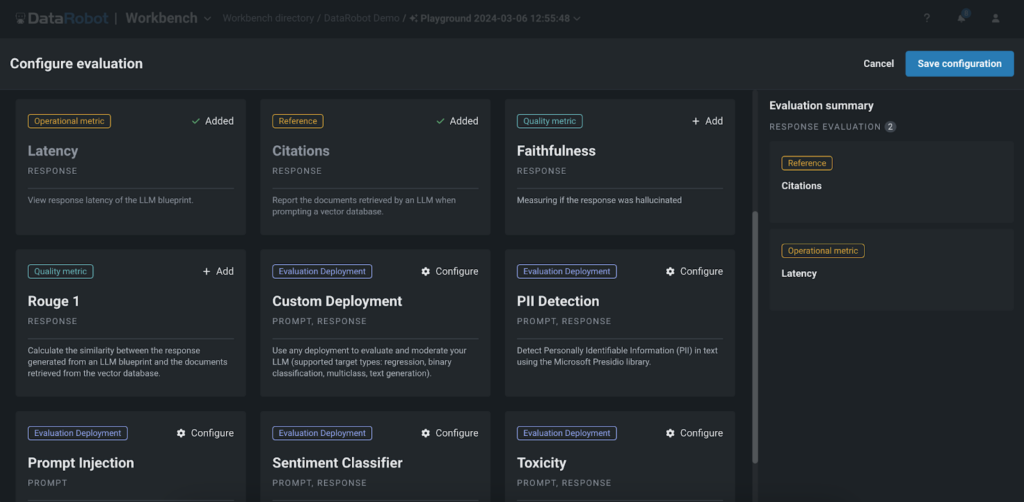
Playground de DataRobot ofrece un conjunto completo de métricas de evaluación que permiten a los usuarios comparar, comparar el rendimiento y clasificar sus experimentos de generación aumentada de recuperación (RAG). Estas métricas incluyen:
- Fidelidad: Esta métrica evalúa con qué precisión las respuestas generadas por el LLM reflejan los datos obtenidos de las bases de datos vectoriales, asegurando la confiabilidad de la información.
- Exactitud: Al comparar las respuestas generadas con la verdad basic, la métrica de corrección evalúa la precisión de los resultados del LLM. Esto es particularmente valioso para aplicaciones donde la precisión es crítica, como en los ámbitos de atención médica, finanzas o authorized, ya que permite a los clientes confiar en la información proporcionada por la aplicación GenAI.
- Citas: Esta métrica rastrea los documentos recuperados por el LLM cuando se solicita la base de datos de vectores, proporcionando información sobre las fuentes utilizadas para generar las respuestas. Ayuda a los usuarios a garantizar que su aplicación aproveche las fuentes más apropiadas, mejorando la relevancia y credibilidad del contenido generado. Los modelos de guardia de Playground pueden ayudar a verificar la calidad y relevancia de las citas utilizadas por los LLM.
- Rojo-1: La métrica Rouge-1 calcula la superposición de unigramas (cada palabra) entre la respuesta generada y los documentos recuperados de las bases de datos vectoriales, lo que permite a los usuarios evaluar la relevancia del contenido generado.
- Costo y latencia: También proporcionamos métricas para realizar un seguimiento del costo y la latencia asociados con la ejecución del LLM, lo que permite a los usuarios optimizar sus experimentos para lograr eficiencia y rentabilidad. Estas métricas ayudan a las organizaciones a encontrar el equilibrio adecuado entre el rendimiento y las restricciones presupuestarias, garantizando la viabilidad de implementar aplicaciones GenAI a escala.
- Modelos de guardia: Nuestra plataforma permite a los usuarios aplicar modelos de protección del Registro DataRobot o modelos personalizados para evaluar las respuestas de LLM. Se pueden agregar modelos como detectores de toxicidad y PII al patio de juegos para evaluar cada resultado de LLM. Esto permite probar fácilmente los modelos de guardia en las respuestas de LLM antes de implementarlos en producción.
Experimentación eficiente
Playground de DataRobot permite a los clientes y desarrolladores de IA experimentar libremente con diferentes LLM, estrategias de fragmentación, métodos de integración y métodos de indicación. Las métricas de evaluación desempeñan un papel essential para ayudar a los usuarios a navegar de manera eficiente en este proceso de experimentación. Al proporcionar un conjunto estandarizado de métricas de evaluación, DataRobot permite a los usuarios comparar fácilmente el rendimiento de diferentes configuraciones y experimentos de LLM. Esto permite a los clientes y creadores de IA tomar decisiones basadas en datos al seleccionar el mejor enfoque para su caso de uso específico, ahorrando tiempo y recursos en el proceso.
Por ejemplo, al experimentar con diferentes estrategias de fragmentación o métodos de integración, los usuarios han podido mejorar significativamente la precisión y relevancia de sus aplicaciones GenAI en escenarios del mundo actual. Este nivel de experimentación es essential para desarrollar soluciones GenAI de alto rendimiento adaptadas a los requisitos específicos de la industria.
Optimización y comentarios de los usuarios
Las métricas de evaluación de Playground actúan como una herramienta valiosa para evaluar el rendimiento de las aplicaciones GenAI. Al analizar métricas como Rouge-1 o citas, los clientes y los creadores de IA pueden identificar áreas donde se pueden mejorar sus modelos, como mejorar la relevancia de las respuestas generadas o garantizar que la aplicación aproveche las fuentes más apropiadas de las bases de datos vectoriales. Estas métricas proporcionan un enfoque cuantitativo para evaluar la calidad de las respuestas generadas.
Además de las métricas de evaluación, Playground de DataRobot permite a los usuarios proporcionar comentarios directos sobre las respuestas generadas a través de calificaciones con el pulgar hacia arriba o hacia abajo. Estos comentarios de los usuarios son el método principal para crear un conjunto de datos de ajuste. Los usuarios pueden revisar las respuestas generadas por el LLM y votar sobre su calidad y relevancia. Las respuestas votadas se utilizan luego para crear un conjunto de datos para ajustar la aplicación GenAI, permitiéndole aprender de las preferencias del usuario y generar respuestas más precisas y relevantes en el futuro. Esto significa que los usuarios pueden recopilar tantos comentarios como necesiten para crear un conjunto de datos completo y de ajuste que refleje las preferencias y requisitos de los usuarios del mundo actual.
Al combinar las métricas de evaluación y los comentarios de los usuarios, los clientes y los creadores de IA pueden tomar decisiones basadas en datos para optimizar sus aplicaciones GenAI. Pueden utilizar las métricas para identificar respuestas de alto rendimiento e incluirlas en el conjunto de datos de ajuste, asegurando que el modelo aprenda de los mejores ejemplos. Este proceso iterativo de evaluación, retroalimentación y ajuste permite a las organizaciones mejorar continuamente sus aplicaciones GenAI y ofrecer experiencias de alta calidad centradas en el usuario.
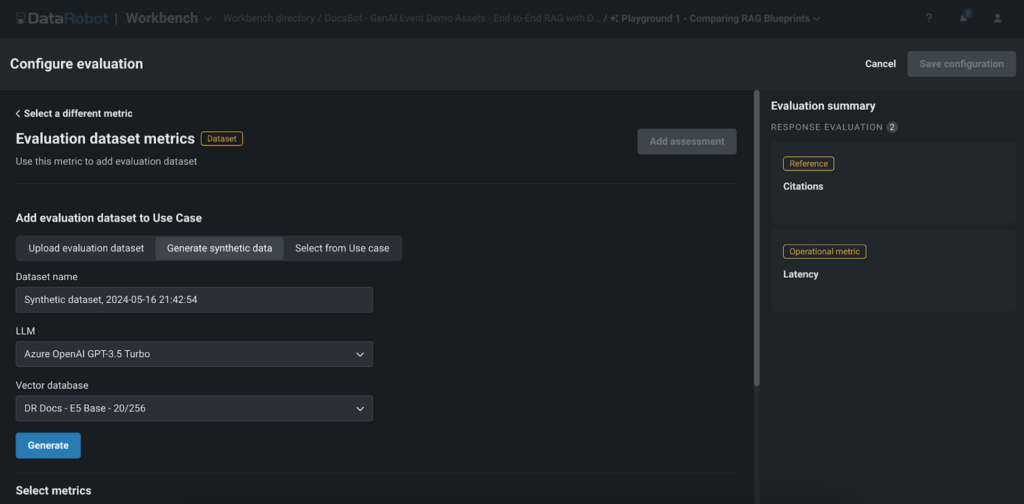
Generación de datos sintéticos para una evaluación rápida
Una de las características destacadas de DataRobot’s Playground es la generación de datos sintéticos para una evaluación de preguntas y respuestas. Esta característica permite a los usuarios crear rápidamente y sin esfuerzo pares de preguntas y respuestas basados en la base de datos de vectores del usuario, lo que les permite evaluar exhaustivamente el rendimiento de sus experimentos RAG sin la necesidad de crear datos manualmente.
La generación de datos sintéticos ofrece varios beneficios clave:
- Ahorro de tiempo: la creación guide de grandes conjuntos de datos puede llevar mucho tiempo. La generación de datos sintéticos de DataRobot automatiza este proceso, ahorra tiempo y recursos valiosos y permite a los clientes y creadores de IA crear prototipos y probar rápidamente sus aplicaciones GenAI.
- Escalabilidad: con la capacidad de generar miles de pares de preguntas y respuestas, los usuarios pueden probar exhaustivamente sus experimentos RAG y garantizar la solidez en una amplia gama de escenarios. Este enfoque de prueba integral ayuda a los clientes y creadores de IA a ofrecer aplicaciones de alta calidad que satisfagan las necesidades y expectativas de sus usuarios finales.
- Evaluación de calidad: al comparar las respuestas generadas con los datos sintéticos, los usuarios pueden evaluar fácilmente la calidad y precisión de su aplicación GenAI. Esto acelera el tiempo de obtención de valor para sus aplicaciones GenAI, lo que permite a las organizaciones llevar sus soluciones innovadoras al mercado más rápidamente y obtener una ventaja competitiva en sus respectivas industrias.
Es importante tener en cuenta que, si bien los datos sintéticos proporcionan una forma rápida y eficiente de evaluar las aplicaciones GenAI, es posible que no siempre capturen toda la complejidad y los matices de los datos del mundo actual. Por lo tanto, es essential utilizar datos sintéticos junto con comentarios de usuarios reales y otros métodos de evaluación para garantizar la solidez y eficacia de la aplicación GenAI.
Conclusión
Las métricas avanzadas de evaluación, pruebas y evaluación de LLM de DataRobot en Playground brindan a los clientes y creadores de IA un poderoso conjunto de herramientas para crear aplicaciones GenAI eficientes, confiables y de alta calidad. Al ofrecer métricas de evaluación integrales, capacidades eficientes de experimentación y optimización, integración de comentarios de los usuarios y generación de datos sintéticos para una evaluación rápida, DataRobot permite a los usuarios desbloquear todo el potencial de los LLM e impulsar resultados significativos.
Con una mayor confianza en el rendimiento del modelo, un tiempo de obtención de valor acelerado y la capacidad de ajustar sus aplicaciones, los clientes y los creadores de IA pueden centrarse en ofrecer soluciones innovadoras que resuelvan problemas del mundo actual y creen valor para sus usuarios finales. Playground de DataRobot, con sus métricas de evaluación avanzadas y características únicas, cambia las reglas del juego en el panorama GenAI, permitiendo a las organizaciones superar los límites de lo que es posible con los modelos de lenguaje grandes.
No pierda la oportunidad de optimizar sus proyectos con la plataforma de prueba y evaluación de LLM más avanzada disponible. Visita Zona de juegos de DataRobot ahora y comience su viaje hacia la creación de aplicaciones GenAI superiores que realmente se destaquen en el competitivo panorama de la IA.
Sobre el autor

Nathaniel Daly es gerente senior de productos en DataRobot y se enfoca en AutoML y productos de collection temporales. Su objetivo es ofrecer avances en ciencia de datos a los usuarios para que puedan aprovechar este valor para resolver problemas empresariales del mundo actual. Tiene una licenciatura en Matemáticas de la Universidad de California, Berkeley.