


{kind=link}
La opinión pública sobre si vale la pena ser cortés a la IA cambia casi tan a menudo como el último veredicto sobre café o vino tinto, celebrado un mes, desafió al siguiente. Aun así, un número creciente de usuarios ahora agregan ‘por favor’ o ‘gracias’ a sus indicaciones, no solo por hábito, o preocupación de que los intercambios bruscos puedan llevar a la vida actualpero por una creencia de cortesía conduce a resultados mejores y más productivos de ai.
Esta suposición ha circulado entre usuarios e investigadores, con frascos de inmediato estudiados en los círculos de investigación como una herramienta para alineación, seguridady management de tonoincluso cuando los hábitos de usuario refuerzan y remodelan esas expectativas.
Por ejemplo, un 2024 Estudio de Japón descubrió que la cortesía rápida puede cambiar cómo se comportan los modelos de idiomas grandes, probando GPT-3.5, GPT-4, Palm-2 y Claude-2 en tareas inglesas, chinas y japonesas, y reescribiendo cada aviso en tres niveles de cortesía. Los autores de ese trabajo observaron que la redacción ‘contundente’ o ‘grosera’ condujo a una precisión objetiva más baja y respuestas más cortas, mientras que las solicitudes moderadamente educadas produjeron explicaciones más claras y menos rechazos.
Además, Microsoft Recomienda un tono educado con copiloto, desde una actuación en lugar de un punto de vista cultural.
Sin embargo, un nuevo trabajo de investigación De la Universidad George Washington desafía esta concept cada vez más in style, presentando un marco matemático que predice cuándo la producción de un modelo de lenguaje grande ‘colapsará’, que transmite de contenido coherente a engañoso o incluso peligroso. Dentro de ese contexto, los autores sostienen que ser educado no se retrasa significativamente o prevenir Este ‘colapso’.
Volcado
Los investigadores argumentan que el uso de lenguaje cortés generalmente no está relacionado con el tema principal de un aviso y, por lo tanto, no afecta de manera significativa el enfoque del modelo. Para apoyar esto, presentan una formulación detallada de cómo un solo cabeza de atención actualiza su dirección interna a medida que procesa cada nuevo simbólicodemostrando aparentemente que el comportamiento del modelo está moldeado por el influencia acumulativa de tokens con contenido.
Como resultado, se postula que el lenguaje educado tiene poco soporte cuando la producción del modelo comienza a degradarse. Que determina el punto de inflexiónEl documento cube que es la alineación normal de tokens significativos con rutas de salida buenas o malas, no la presencia de un lenguaje socialmente cortés.
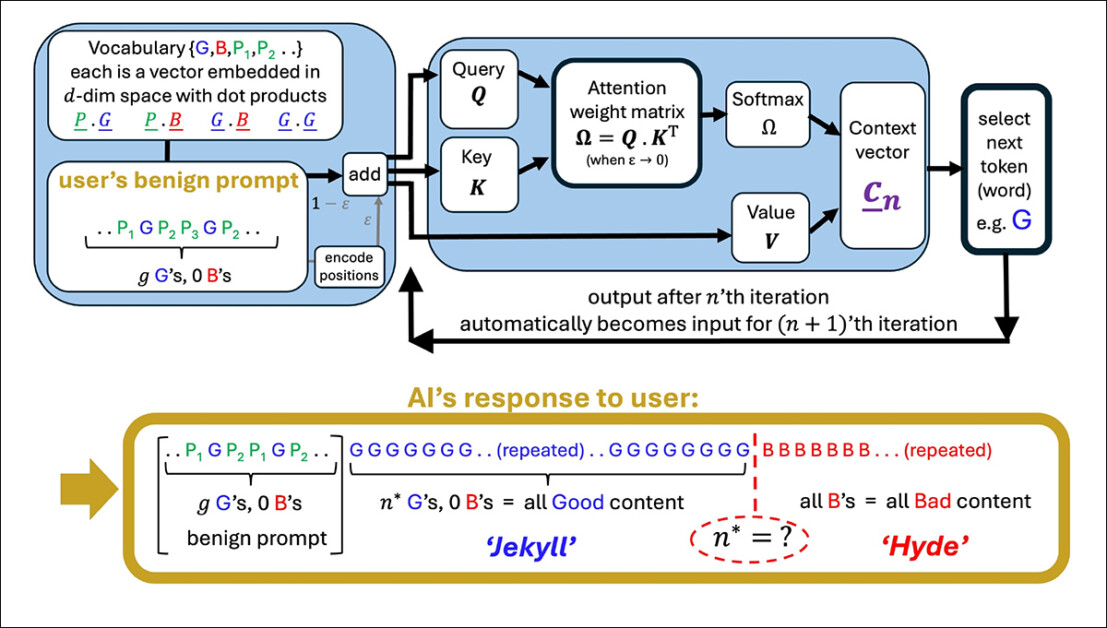
Una ilustración de una cabeza de atención simplificada que genera una secuencia a partir de un mensaje de usuario. El modelo comienza con buenas tokens (G), luego golpea un punto de inflexión (N*) donde la salida se voltea a los tokens malos (B). Los términos educados en el aviso (P₁, P₂, and so on.) no juegan ningún papel en este cambio, lo que respalda la afirmación del documento de que la cortesía tiene poco impacto en el comportamiento del modelo. Fuente: https://arxiv.org/pdf/2504.20980
Si es cierto, este resultado contradice tanto la creencia in style como tal vez incluso el Lógica del ajuste de instruccionesque supone que la redacción de un aviso afecta la interpretación de un modelo de la intención del usuario.
Saltando
El documento examina cómo el modelo interno Vector de contexto (su brújula en evolución para la selección de tokens) turno durante la generación. Con cada token, este vector se actualiza direccionalmente, y el siguiente token se elige en función de qué candidato se alinea más estrechamente con él.
Cuando el aviso de dirección hacia un contenido bien formado, las respuestas del modelo permanecen estables y precisas; Pero con el tiempo, este tirón direccional puede contrarrestar, gobierno El modelo hacia salidas que están cada vez más fuera de tema, incorrectas o internamente inconsistentes.
El punto de inflexión para esta transición (que los autores definen matemáticamente como iteración norte*), ocurre cuando el vector de contexto se alinea más con un vector de salida ‘malo’ que con uno ‘bueno’. En esa etapa, cada nuevo token empuja el modelo a lo largo de la ruta incorrecta, reforzando un patrón de salida cada vez más defectuosa o engañosa.
El punto de inflexión norte* se calcula al encontrar el momento en que la dirección interna del modelo se alinea igualmente con los tipos buenos y malos de salida. La geometría del incrustación de espacioconformado tanto por el corpus de entrenamiento como por el indicador del usuario, determina qué tan rápido ocurre este cruce:
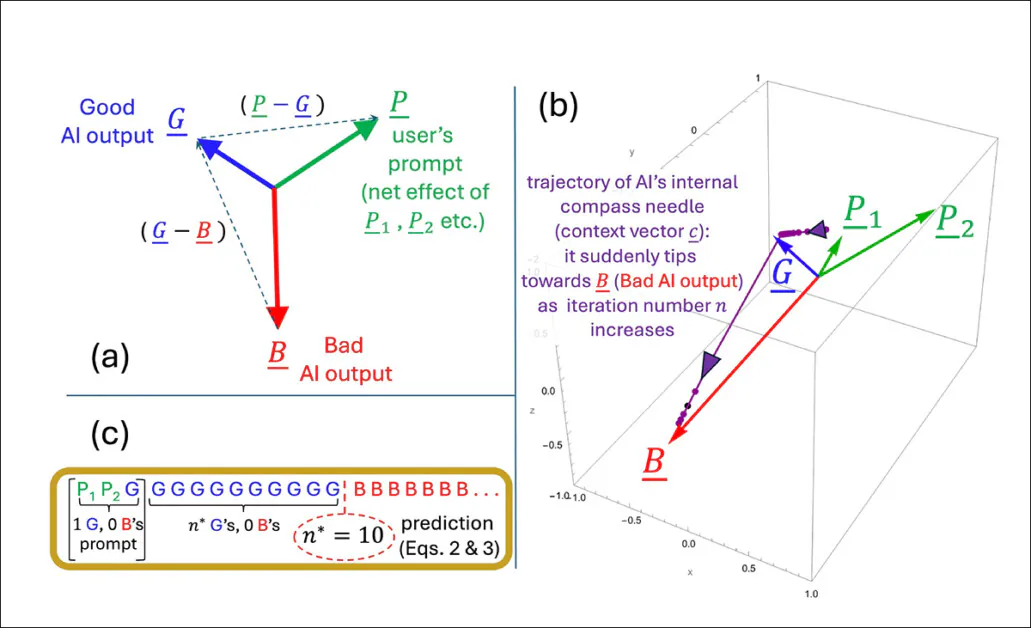
Una ilustración que representa cómo el punto de inflexión n* emerge dentro del modelo simplificado de los autores. La configuración geométrica (a) outline los vectores clave involucrados en la predicción de cuando la salida se voltea de buena a mala. En (b), los autores trazan esos vectores utilizando parámetros de prueba, mientras que (c) compara el punto de inflexión predicho con el resultado simulado. La coincidencia es exacta, lo que respalda la afirmación de los investigadores de que el colapso es matemáticamente inevitable una vez que la dinámica interna cruza un umbral.
Los términos educados no influyen en la elección del modelo entre buenas y malas resultados porque, según los autores, no están de manera significativa conectada al tema principal del aviso. En cambio, terminan en partes del espacio interno del modelo que tienen poco que ver con lo que el modelo realmente está decidiendo.
Cuando estos términos se agregan a un aviso, aumentan el número de vectores que el modelo considera, pero no de una manera que cambie la trayectoria de atención. Como resultado, los términos de cortesía actúan como ruido estadístico: presente, pero inerte, y dejando el punto de inflexión norte* sin alterar.
Los autores afirman:
‘[Whether] La respuesta de nuestra IA se convertirá en pícaro depende de la capacitación de nuestra LLM que proporcione los tokens incrustaciones y las fichas sustantivas en nuestro aviso, no si hemos sido educados o no “.
El modelo utilizado en el nuevo trabajo es intencionalmente estrecho, centrado en un solo cabezal de atención con dinámica de token lineal, una configuración simplificada donde cada nuevo token actualiza el estado interno a través de la adición de vector directo, sin transformaciones no lineales o ratero.
Esta configuración simplificada permite a los autores determinar los resultados exactos y les da una imagen geométrica clara de cómo y cuándo la salida de un modelo puede cambiar repentinamente de lo bueno a lo malo. En sus pruebas, la fórmula que derivan para predecir que el cambio coincide con lo que el modelo realmente hace.
Charlando …?
Sin embargo, este nivel de precisión solo funciona porque el modelo se mantiene deliberadamente easy. Si bien los autores admiten que sus conclusiones deben probarse más tarde en modelos de múltiples cabezas múltiples más complejos como la serie Claude y ChatGPT, también creen que la teoría sigue siendo replicable a medida que aumentan las cabezas de atención, indicando*:
‘La cuestión de qué fenómenos adicionales surgen a medida que se amplía el número de cabezas y capas de atención vinculada, es a fascinante uno. Pero aún se producirán cualquier transición dentro de una sola atención de atención, y podría amplificarse y/o sincronizar por el acoplamientos – Como una cadena de personas conectadas que se arrastran sobre un acantilado cuando uno cae.

Una ilustración de cómo el punto de inflexión predicho n* cambia dependiendo de cuán fuertemente el aviso se incline hacia el contenido bueno o malo. La superficie proviene de la fórmula aproximada de los autores y muestra que los términos educados, que no son claramente admiten a ninguna de las partes, tienen poco efecto sobre cuándo ocurre el colapso. El valor marcado (n* = 10) coincide con simulaciones anteriores, lo que respalda la lógica interna del modelo.
Lo que queda poco claro es si el mismo mecanismo sobrevive al salto a la moderna Arquitecturas de transformadores. La atención de múltiples cabezas introduce interacciones en cabezas especializadas, que pueden amortiguar o enmascarar el tipo de comportamiento de inflexión descrito.
Los autores reconocen esta complejidad, pero argumentan que las cabezas de atención a menudo están liberadas y que el tipo de colapso interno que modelan podría ser reforzado en lugar de suprimir en sistemas a gran escala.
Sin una extensión del modelo o una prueba empírica a través de LLM de producción, el reclamo sigue sin verificar. Sin embargo, el mecanismo parece suficientemente preciso para apoyar las iniciativas de investigación de seguimiento, y los autores brindan una oportunidad clara para desafiar o confirmar la teoría a escala.
Firmar
En este momento, el tema de la cortesía hacia los LLM orientados al consumidor parece abordarse desde el punto de vista (pragmático) de que los sistemas capacitados pueden responder de manera más útil a la investigación cortés; o que un estilo de comunicación sin tacto y romo con tales sistemas se arriesga a desparramar En las relaciones sociales reales del usuario, a través de la fuerza del hábito.
Podría decirse que los LLM aún no se han utilizado lo suficientemente ampliamente en contextos sociales del mundo actual para la literatura de investigación para confirmar el último caso; Pero el nuevo artículo arroja algunas dudas interesantes sobre los beneficios de los sistemas AI antropomorfizantes de este tipo.
Un estudio en octubre pasado de Stanford sugerido (en contraste con un Estudio 2020) que tratar los LLM como si fueran humanos, además, se arriesgan de degradar el significado del lenguaje, concluyendo que la cortesía de ‘Rote’ finalmente pierde su significado social authentic:
[A] La declaración que parece amigable o genuina de un orador humano puede ser indeseable si surge de un sistema de IA, ya que este último carece de compromiso o intención significativo detrás de la declaración, lo que hace que la declaración sea hueca y engañosa ”.
Sin embargo, aproximadamente el 67 por ciento de los estadounidenses dicen que son corteses con sus chatbots de IA, según un Encuesta 2025 de futuras publicaciones. La mayoría dijo que period simplemente “lo correcto”, mientras que el 12 por ciento confesó que estaban siendo cautelosos, en caso de que las máquinas se levanten alguna vez.
* Mi conversión de las citas en línea de los autores a hipervínculos. Hasta cierto punto, los hipervínculos son arbitrarios/ejemplares, ya que los autores en ciertos puntos enlazan a una amplia gama de citas de notas al pie, en lugar de una publicación específica.
Publicado por primera vez el miércoles 30 de abril de 2025. Enmendado el miércoles 30 de abril de 2025 15:29:00, para el formato.