


{kind=link}
Más rápido, más inteligente y con mayor capacidad de respuesta Aplicaciones de IA – eso es lo que sus usuarios esperan. Pero cuando los modelos de lenguajes grandes (LLM) tardan en responder, la experiencia del usuario se ve afectada. Cada milisegundo cuenta.
Con los puntos finales de inferencia de alta velocidad de Cerebras, puede reducir la latencia, acelerar las respuestas del modelo y mantener la calidad a escala con modelos como Llama 3.1-70B. Si sigue unos sencillos pasos, podrá personalizar e implementar sus propios LLM, lo que le brindará el management para optimizar tanto la velocidad como la calidad.
En este weblog, le explicaremos cómo:
- Configure Llama 3.1-70B en el Área de juegos DataRobot LLM.
- Genere y aplique una clave API para aprovechar Cerebras para realizar inferencias.
- Personalice e implemente aplicaciones más inteligentes y rápidas.
Al last, estará listo para implementar LLM que brinden velocidad, precisión y capacidad de respuesta en tiempo actual.
Cree prototipos, personalice y pruebe LLM en un solo lugar
La creación de prototipos y pruebas de modelos de IA generativa a menudo requieren un mosaico de herramientas desconectadas. Pero con un entorno unificado e integrado para LLMtécnicas de recuperación y métricas de evaluación, puede pasar de una thought a un prototipo funcional más rápido y con menos obstáculos.
Este proceso simplificado significa que puede concentrarse en crear aplicaciones de IA efectivas y de alto impacto sin la molestia de reunir herramientas de diferentes plataformas.
Analicemos un caso de uso para ver cómo puede aprovechar estas capacidades para desarrollar aplicaciones de IA más inteligentes y rápidas.
Caso de uso: acelerar la interferencia LLM sin sacrificar la calidad
La baja latencia es esencial para crear aplicaciones de IA rápidas y con capacidad de respuesta. Pero las respuestas aceleradas no tienen por qué ir en detrimento de la calidad.
la velocidad de Inferencia de cerebros supera a otras plataformas, lo que permite a los desarrolladores crear aplicaciones que se sienten fluidas, receptivas e inteligentes.
Cuando se combina con una experiencia de desarrollo intuitiva, puedes:
- Reducir la latencia LLM para interacciones más rápidas con el usuario.
- Experimente de manera más eficiente con nuevos modelos y flujos de trabajo.
- Implementar aplicaciones que responden instantáneamente a las acciones del usuario.
Los siguientes diagramas muestran el rendimiento de Cerebras en Llama 3.1-70B, lo que ilustra tiempos de respuesta más rápidos y una latencia más baja que otras plataformas. Esto permite una iteración rápida durante el desarrollo y un rendimiento en tiempo actual en producción.
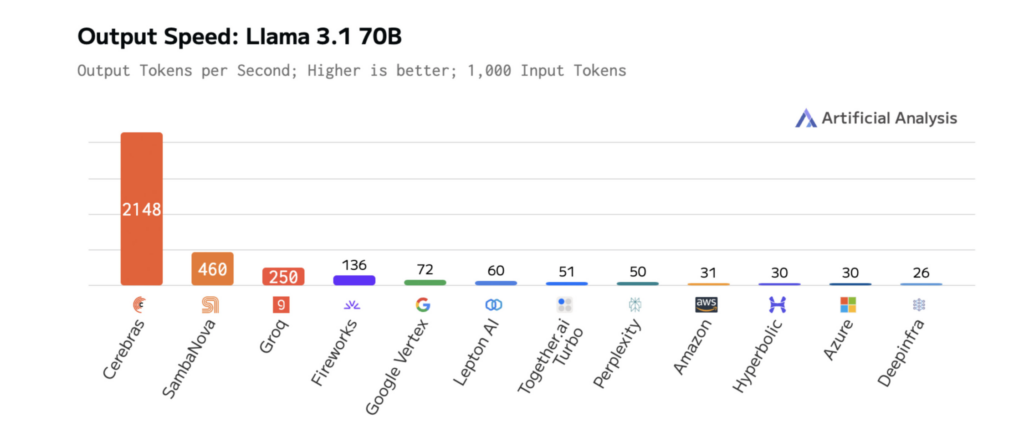
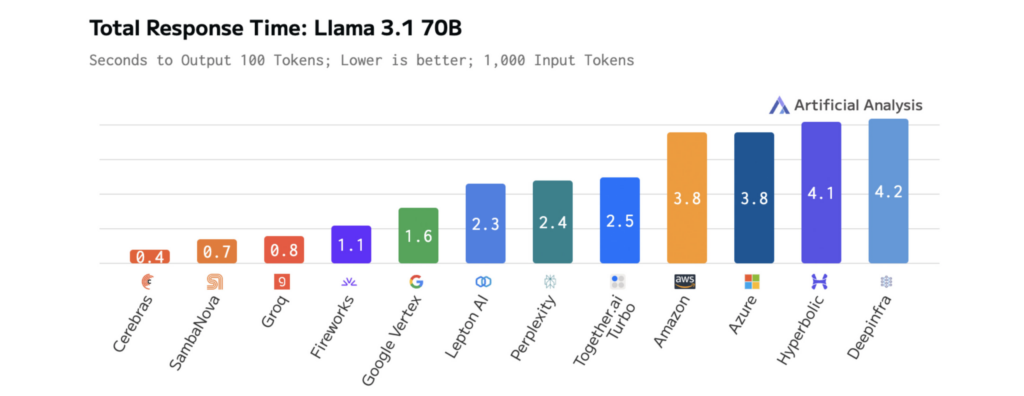
Cómo el tamaño del modelo afecta la velocidad y el rendimiento de LLM
A medida que los LLM crecen y se vuelven más complejos, sus resultados se vuelven más relevantes y completos, pero esto tiene un costo: mayor latencia. Cerebras aborda este desafío con cálculos optimizados, transferencia de datos optimizada y decodificación inteligente diseñada para la velocidad.
Estas mejoras en la velocidad ya están transformando las aplicaciones de IA en industrias como la farmacéutica y la IA de voz. Por ejemplo:
- GlaxoSmithKline (GSK) utiliza Cerebras Inference para acelerar el descubrimiento de fármacos, impulsando una mayor productividad.
- package en vivo ha impulsado el rendimiento del canal de modo de voz de ChatGPT, logrando tiempos de respuesta más rápidos que las soluciones de inferencia tradicionales.
Los resultados son mensurables. En Llama 3.1-70B, Cerebras ofrece una inferencia 70 veces más rápida que las GPU básicas, lo que permite interacciones más fluidas en tiempo actual y ciclos de experimentación más rápidos.
Este rendimiento está impulsado por el motor Wafer-Scale Engine (WSE-3) de tercera generación de Cerebras, un procesador personalizado diseñado para optimizar las operaciones de álgebra lineal dispersa basadas en tensores que impulsan la inferencia LLM.
Al priorizar el rendimiento, la eficiencia y la flexibilidad, el WSE-3 garantiza resultados más rápidos y consistentes durante el desempeño del modelo.
La velocidad de Cerebras Inference cut back la latencia de las aplicaciones de IA impulsadas por sus modelos, lo que permite un razonamiento más profundo y experiencias de usuario más receptivas. Acceder a estos modelos optimizados es easy: están alojados en Cerebras y se puede acceder a ellos a través de un único punto last, por lo que puede comenzar a aprovecharlos con una configuración mínima.

Paso a paso: cómo personalizar e implementar Llama 3.1-70B para IA de baja latencia
Integración de LLM como Llama 3.1-70B de Cerebras en robotic de datos le permite personalizar, probar e implementar modelos de IA en solo unos pocos pasos. Este proceso respalda un desarrollo más rápido, pruebas interactivas y un mayor management sobre la personalización de LLM.
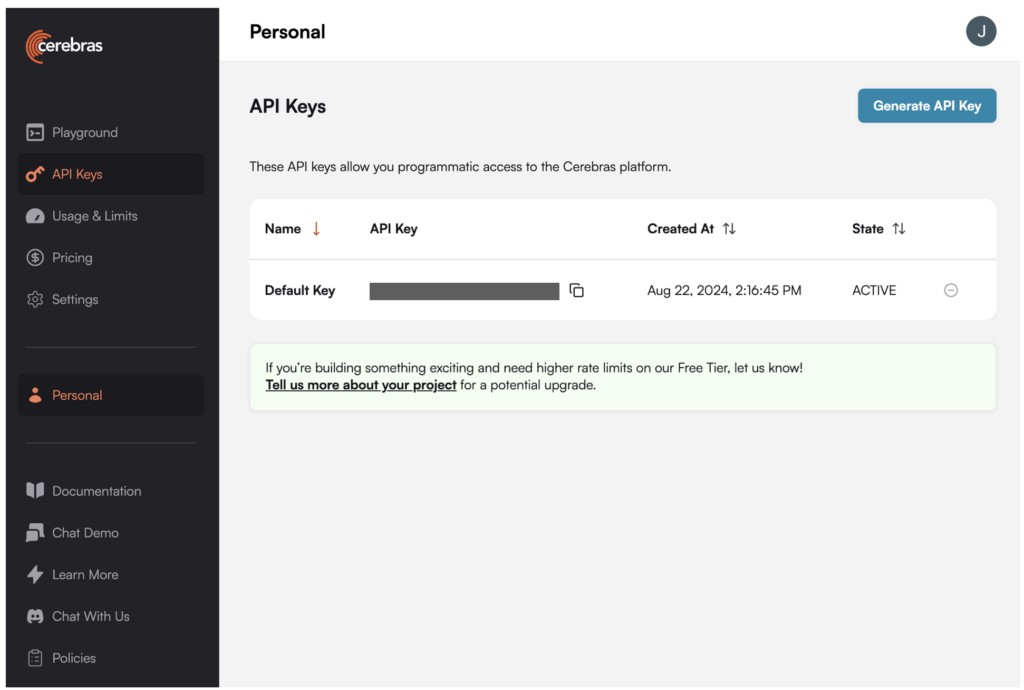
1. Generar una clave API para Llama 3.1-70B en la plataforma Cerebras.
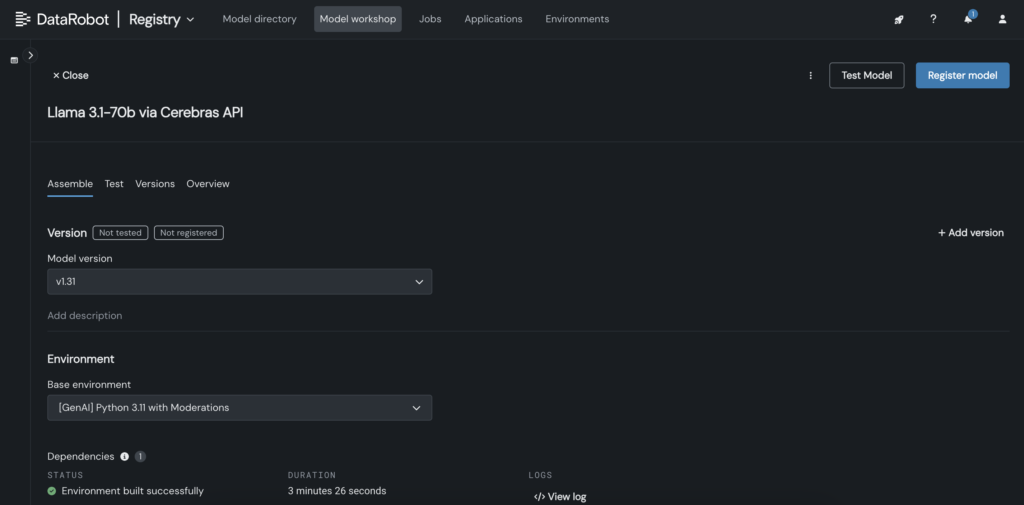
2. En DataRobot, cree un modelo personalizado en Mannequin Workshop que llame al punto last de Cerebras donde está alojado Llama 3.1 70B.
3. Dentro del modelo personalizado, coloque la clave API de Cerebras dentro del archivo customized.py.
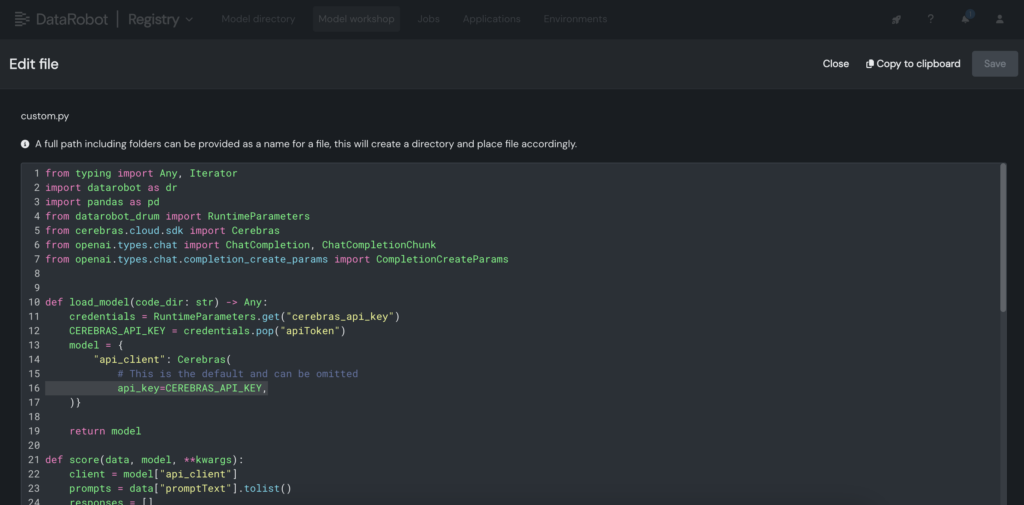
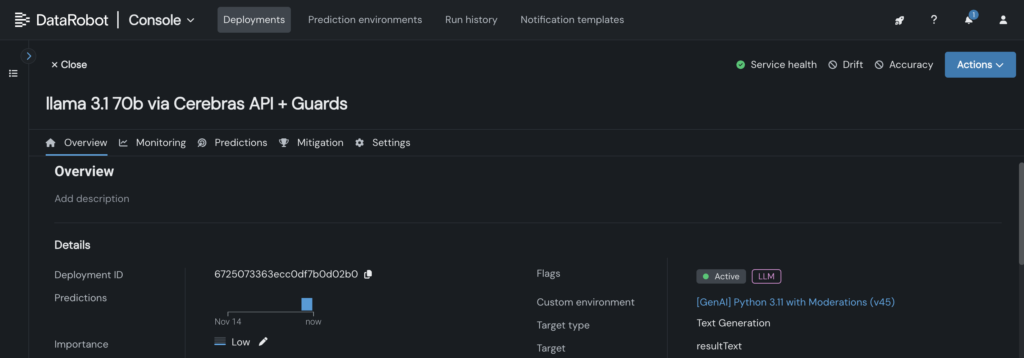
4. Implemente el modelo personalizado en un punto last en la consola de DataRobot, permitiendo que los planos de LLM lo aprovechen para realizar inferencias.
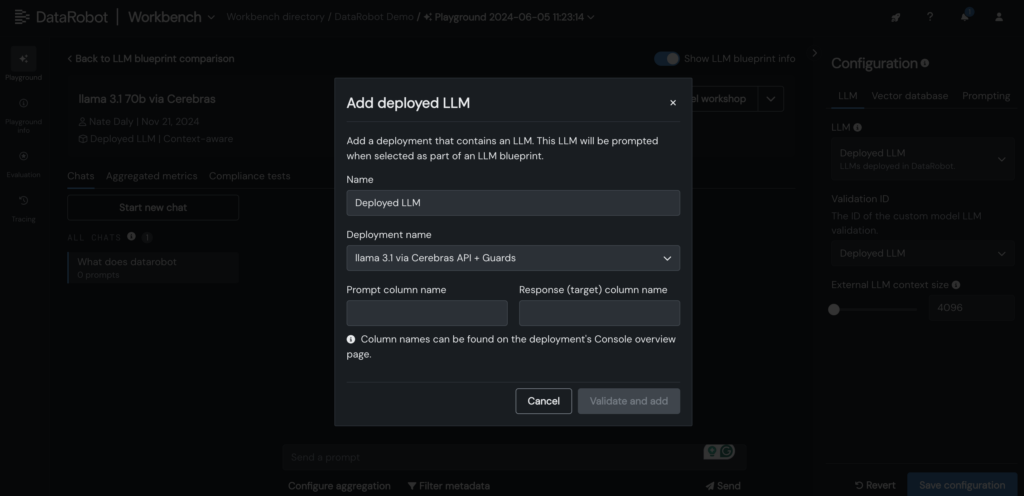
5. Agregue su Cerebras LLM implementado al plano de LLM en DataRobot LLM Playground para comenzar a chatear con Llama 3.1 -70B.
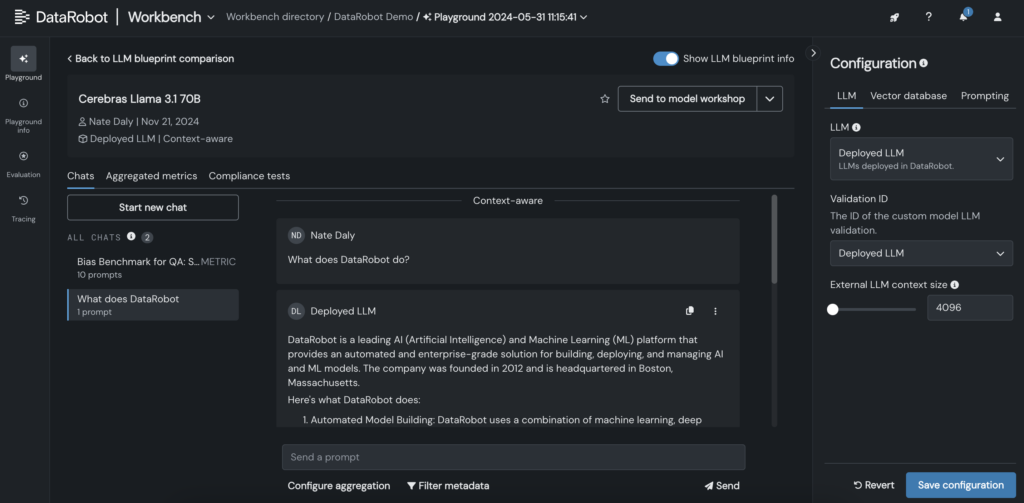
6. Una vez que el LLM se agrega al plano, pruebe las respuestas ajustando los parámetros de solicitud y recuperación, y examine los resultados con otros LLM directamente en la GUI de DataRobot.
Amplíe los límites de la inferencia LLM para sus aplicaciones de IA
Implementar LLM como Llama 3.1-70B con baja latencia y capacidad de respuesta en tiempo actual no es una tarea fácil. Pero con las herramientas y los flujos de trabajo adecuados, puedes lograr ambas cosas.
Al integrar los LLM en LLM Playground de DataRobot y aprovechar la inferencia optimizada de Cerebras, puede simplificar la personalización, acelerar las pruebas y reducir la complejidad, todo mientras mantiene el rendimiento que esperan sus usuarios.
A medida que los LLM crecen y se vuelven más poderosos, contar con un proceso simplificado de prueba, personalización e integración será esencial para los equipos que buscan mantenerse a la vanguardia.
Exploralo tu mismo. Acceso Inferencia de cerebrosgenera tu clave API y comienza a construir Aplicaciones de IA en DataRobot.
Sobre el autor

Kumar Venkateswar es vicepresidente de Producto, Plataforma y Ecosistema de DataRobot. Dirige la gestión de productos para los servicios fundamentales y las asociaciones de ecosistemas de DataRobot, cerrando las brechas entre la infraestructura eficiente y las integraciones que maximizan los resultados de la IA. Antes de DataRobot, Kumar trabajó en Amazon y Microsoft, incluidos equipos líderes de gestión de productos para Amazon SageMaker y Amazon Q Enterprise.

Nathaniel Daly es gerente senior de productos en DataRobot y se enfoca en AutoML y productos de sequence temporales. Su objetivo es ofrecer avances en ciencia de datos a los usuarios para que puedan aprovechar este valor para resolver problemas empresariales del mundo actual. Tiene una licenciatura en Matemáticas de la Universidad de California, Berkeley.