


{kind=link}
Los humanos se destacan en el procesamiento de grandes cantidades de información visible, una habilidad essential para lograr la inteligencia synthetic normal (AGI). A lo largo de décadas, los investigadores de IA han desarrollado sistemas de respuesta visible a preguntas (VQA) para interpretar escenas dentro de imágenes individuales y responder preguntas relacionadas. Si bien los avances recientes en los modelos básicos han cerrado significativamente la brecha entre el procesamiento visible humano y el de la máquina, el VQA convencional se ha restringido a razonar solo sobre soltero imágenes a la vez en lugar de colecciones completas de datos visuales.
Esta limitación plantea desafíos en escenarios más complejos. Tomemos, por ejemplo, los desafíos de discernir patrones en colecciones de imágenes médicas, monitorear la deforestación a través de imágenes satelitales, mapear cambios urbanos usando datos de navegación autónoma, analizar elementos temáticos en grandes colecciones de arte o comprender el comportamiento del consumidor a partir de imágenes de vigilancia de tiendas minoristas. Cada uno de estos escenarios implica no sólo el procesamiento visible de cientos o miles de imágenes, sino que también requiere el procesamiento de imágenes cruzadas de estos hallazgos. Para abordar esta brecha, este proyecto se centra en la tarea de “Respuesta a preguntas con imágenes múltiples” (MIQA), que excede el alcance de los sistemas VQA tradicionales.

Pajares visuales: el primer punto de referencia Needle-In-A-Haystack (NIAH) “centrado en lo visible” diseñado para evaluar rigurosamente modelos multimodales grandes (LMM) en el procesamiento de información visible de contexto prolongado.
¿Cómo comparar los modelos VQA en MIQA?
El desafío “Needle-In-A-Haystack” (NIAH) se ha convertido recientemente en uno de los paradigmas más populares para evaluar la capacidad de LLM para procesar entradas que contienen “contextos largos”, grandes conjuntos de datos de entrada (como documentos largos, movies o cientos de imágenes). En esta tarea, la información esencial (“la aguja”), que contiene la respuesta a una pregunta específica, está incrustada dentro de una gran cantidad de datos (“el pajar”). Luego, el sistema debe recuperar la información relevante y responder la pregunta correctamente.
Google introdujo el primer punto de referencia NIAH para razonamiento visible en Gemini-v1.5 informe técnico. En este informe, pidieron a sus modelos que recuperaran texto superpuesto en un solo fotograma de un vídeo grande. Resulta que los modelos existentes funcionan bastante bien en esta tarea, principalmente debido a sus sólidas capacidades de recuperación de OCR. Pero ¿y si hacemos preguntas más visuales? ¿Los modelos siguen funcionando tan bien?
¿Qué es el punto de referencia de Visible Haystacks (VH)?
Con el fin de evaluar las capacidades de razonamiento de contexto largo “centradas en lo visible”, presentamos el punto de referencia “Visible Haystacks (VH)”. Este nuevo punto de referencia está diseñado para evaluar modelos multimodales grandes (LMM) en formato visible. recuperación y razonamiento en grandes conjuntos de imágenes no correlacionadas. VH presenta aproximadamente 1.000 pares binarios de preguntas y respuestas, y cada conjunto contiene entre 1.000 y 10.000 imágenes. A diferencia de los puntos de referencia anteriores que se centraban en la recuperación y el razonamiento textual, las preguntas de VH se centran en identificar la presencia de contenido visible específico, como objetos, utilizando imágenes y anotaciones del conjunto de datos COCO.
El punto de referencia de VH se divide en dos desafíos principales, cada uno de los cuales está diseñado para probar la capacidad del modelo para localizar y analizar con precisión imágenes relevantes antes de responder a las consultas. Hemos diseñado cuidadosamente el conjunto de datos para garantizar que adivinar o confiar en el razonamiento de sentido común sin ver la imagen no obtenga ninguna ventaja (es decir, lo que resulta en una tasa de precisión del 50 % en una tarea de management de calidad binaria).
-
Desafío de una sola aguja: Sólo existe una imagen de aguja en el pajar de imágenes. La pregunta se components como: “Para la imagen con el objeto ancla, ¿hay un objeto objetivo?”
-
Desafío de múltiples agujas: Existen de dos a cinco imágenes de agujas en el pajar de imágenes. La pregunta se components como: “Para todas las imágenes con el objeto ancla, ¿contienen todas el objeto de destino?” o “Para todas las imágenes con el objeto ancla, ¿alguna de ellas contiene el objeto de destino?”
Tres hallazgos importantes de los VH
El punto de referencia Visible Haystacks (VH) revela desafíos importantes que enfrentan los modelos multimodales grandes (LMM) actuales al procesar entradas visuales extensas. En nuestros experimentos En los modos de una y varias agujas, evaluamos varios métodos propietarios y de código abierto, incluidos LLaVA-v1.5, GPT-4o, Claude-3 Opusy Géminis-v1.5-pro. Además, incluimos una línea de base de “Subtítulos”, que emplea un enfoque de dos etapas en el que las imágenes se subtitulan inicialmente usando LLaVA, seguido de responder la pregunta usando el contenido de texto de los subtítulos con llama3. A continuación se presentan tres concepts fundamentales:
-
Luchas con los distractores visuales
En configuraciones de una sola aguja, se observó una disminución notable en el rendimiento a medida que aumentaba la cantidad de imágenes, a pesar de mantener una alta precisión de Oracle, un escenario ausente en los puntos de referencia anteriores de estilo Gemini basados en texto. Esto muestra que los modelos existentes pueden tener dificultades principalmente con la recuperación visible, especialmente en presencia de distractores visuales desafiantes. Además, es essential resaltar las limitaciones de los LMM de código abierto como LLaVA, que solo pueden manejar hasta tres imágenes debido a un límite de longitud de contexto de 2K. Por otro lado, los modelos propietarios como Gemini-v1.5 y GPT-4o, a pesar de sus afirmaciones de capacidades de contexto extendido, a menudo no logran administrar las solicitudes cuando el recuento de imágenes excede 1K, debido a los límites de tamaño de la carga útil cuando se usa la llamada API.
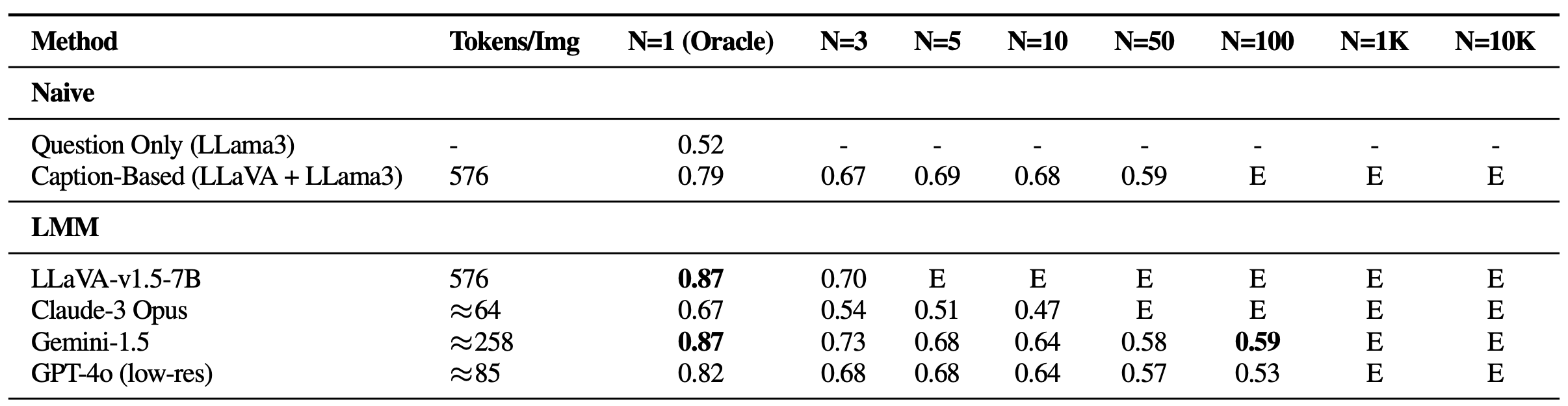
Rendimiento en VH para preguntas con una sola aguja. Todos los modelos experimentan una caída significativa a medida que aumenta el tamaño del pajar (N), lo que sugiere que ninguno de ellos es resistente a los distractores visuales. E: Excede la longitud del contexto. -
Dificultad para razonar en varias imágenes
Curiosamente, todos los métodos basados en LMM mostraron un rendimiento débil con más de 5 imágenes en management de calidad de una sola imagen y todas las configuraciones de múltiples agujas en comparación con un enfoque básico que encadena un modelo de subtítulos (LLaVA) con un agregador LLM (Llama3). Esta discrepancia sugiere que, si bien los LLM son capaces de integrar subtítulos de contexto largo de manera efectiva, las soluciones existentes basadas en LMM son inadecuadas para procesar e integrar información en múltiples imágenes. En specific, el rendimiento se deteriora enormemente en escenarios de múltiples imágenes, con Claude-3 Opus mostrando resultados débiles solo con imágenes de Oracle, y Gemini-1.5/GPT-4o cayendo al 50% de precisión (como una suposición aleatoria) con conjuntos más grandes de 50 imágenes.

Resultados en VH para preguntas con múltiples agujas. Todos los modelos con conciencia visible funcionan mal, lo que indica que a los modelos les resulta difícil integrar implícitamente información visible. -
Fenómenos en el dominio visible
Finalmente, descubrimos que la precisión de los LMM se ve enormemente afectada por la posición de la imagen de la aguja dentro de la secuencia de entrada. Por ejemplo, LLaVA muestra un mejor rendimiento cuando la imagen de la aguja se coloca inmediatamente antes de la pregunta; de lo contrario, sufre una caída de hasta el 26,5 %. Por el contrario, los modelos propietarios generalmente funcionan mejor cuando la imagen se coloca al principio, experimentando una disminución de hasta un 28,5% cuando no. Este patrón se hace eco del “perdido en el medio” Fenómeno observado en el campo del procesamiento del lenguaje pure (PNL), donde la información essential ubicada al principio o al closing del contexto influye en el rendimiento del modelo. Este problema no fue evidente en evaluaciones NIAH anteriores al estilo Gemini, que solo requirieron recuperación de texto y razonamiento, lo que subraya los desafíos únicos que plantea nuestro punto de referencia VH.
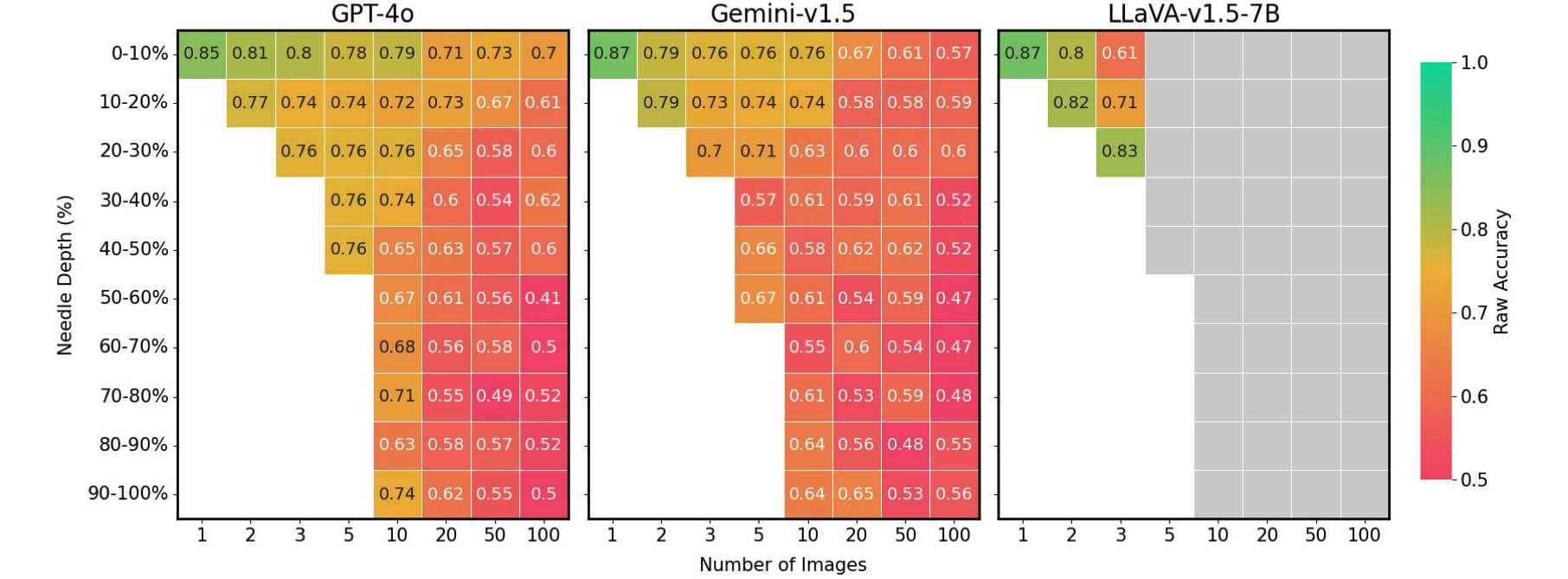
Posición de la aguja versus rendimiento en VH para diversas configuraciones de imagen. Los LMM existentes muestran una caída de rendimiento de hasta un 41 % cuando la aguja no está en la posición best. Cuadros grises: excede la longitud del contexto.
MIRAGE: una solución basada en RAG para mejorar el rendimiento de los VH
Con base en los resultados experimentales anteriores, está claro que los desafíos centrales de las soluciones existentes en MIQA radican en la capacidad de (1) con precisión recuperar imágenes relevantes de un vasto conjunto de imágenes potencialmente no relacionadas sin sesgos posicionales y (2) integrar información visible relevante de estas imágenes para responder correctamente la pregunta. Para abordar estos problemas, presentamos un paradigma de capacitación easy y de código abierto de una sola etapa, “MIRAGE” (Generación Aumentada de Recuperación de Imágenes Múltiples), que extiende la LLaVA modelo para manejar tareas MIQA. La siguiente imagen muestra la arquitectura de nuestro modelo.
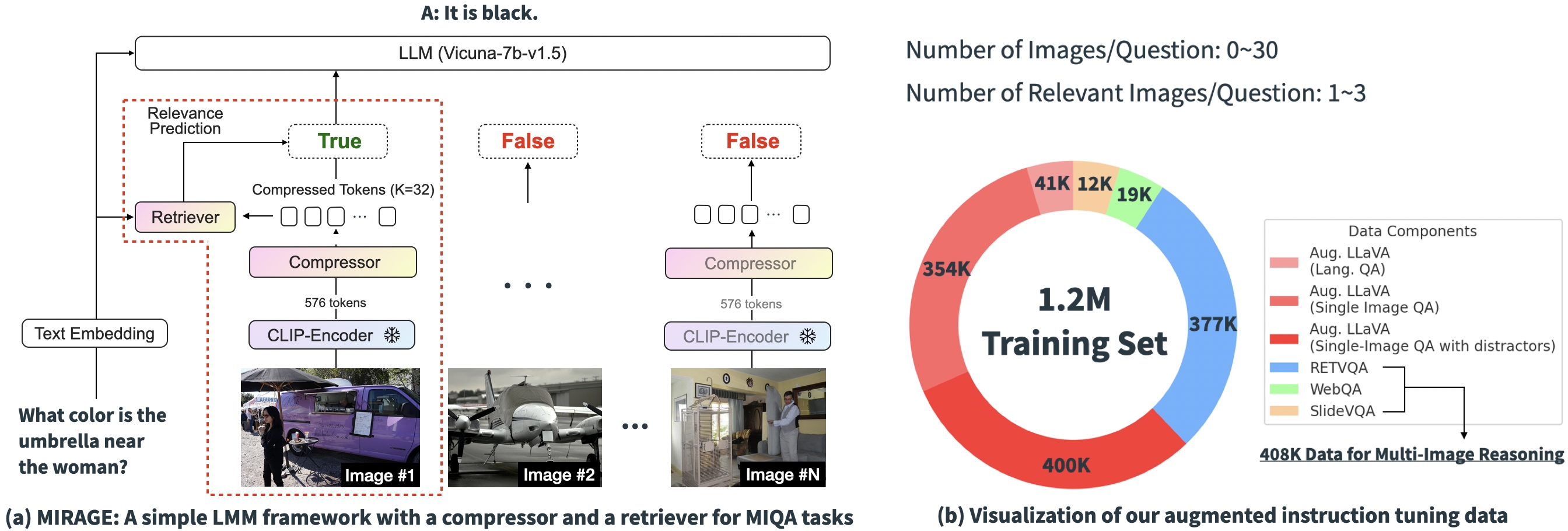
Nuestro paradigma propuesto consta de varios componentes, cada uno de ellos diseñado para aliviar problemas clave en la tarea MIQA:
-
Comprimir codificaciones existentes: El paradigma MIRAGE aprovecha un modelo de compresión con reconocimiento de consultas para reducir los tokens del codificador visible a un subconjunto más pequeño (10 veces más pequeño), lo que permite más imágenes en la misma longitud de contexto.
-
Emplear un recuperador para filtrar mensajes irrelevantes: MIRAGE utiliza un recuperador entrenado en línea con el ajuste fino de LLM, para predecir si una imagen será relevante y eliminar dinámicamente imágenes irrelevantes.
-
Datos de entrenamiento de múltiples imágenes: MIRAGE aumenta los datos de ajuste fino de instrucciones de una sola imagen existentes con datos de razonamiento de múltiples imágenes y datos de razonamiento sintéticos de múltiples imágenes.
Resultados
Revisamos el punto de referencia de VH con MIRAGE. Además de ser capaz de manejar imágenes de 1K o 10K, MIRAGE logra un rendimiento de vanguardia en la mayoría de las tareas con una sola aguja, a pesar de tener una columna vertebral de management de calidad de una sola imagen más débil con solo 32 tokens por imagen.
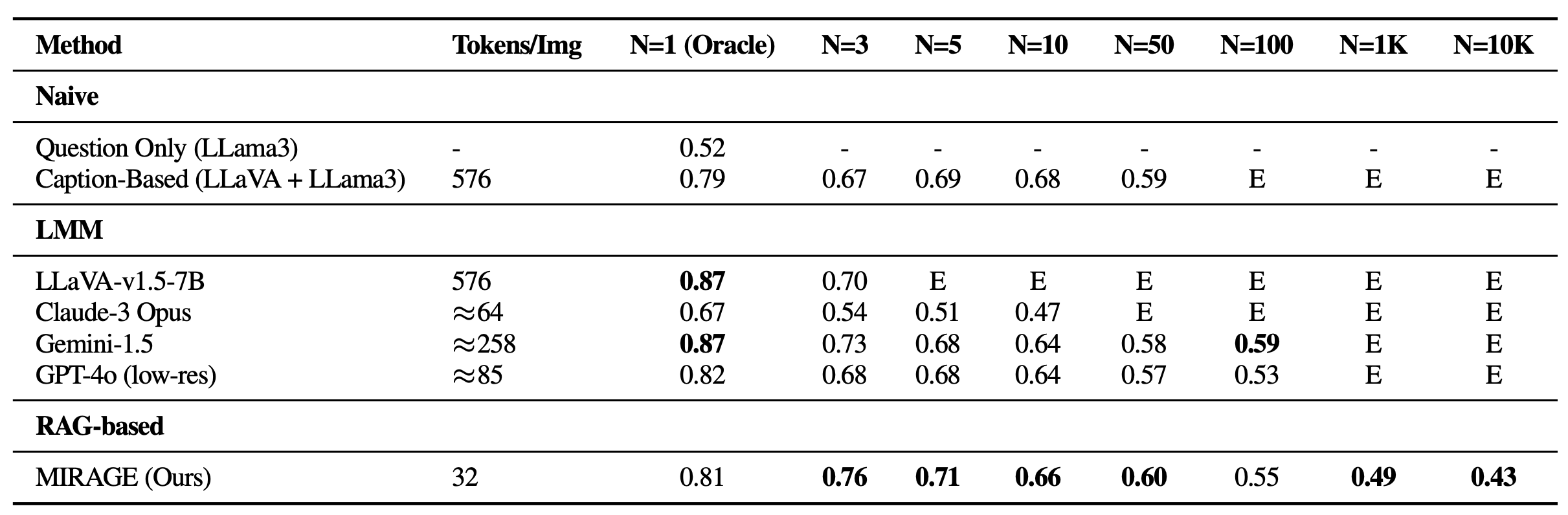
También comparamos MIRAGE y otros modelos basados en LMM en una variedad de tareas VQA. En tareas de múltiples imágenes, MIRAGE demuestra sólidas capacidades de recuperación y precisión, superando significativamente a competidores fuertes como GPT-4, Gemini-v1.5 y el Modelo de mundo grande (LWM). Además, muestra un rendimiento competitivo de management de calidad de una sola imagen.
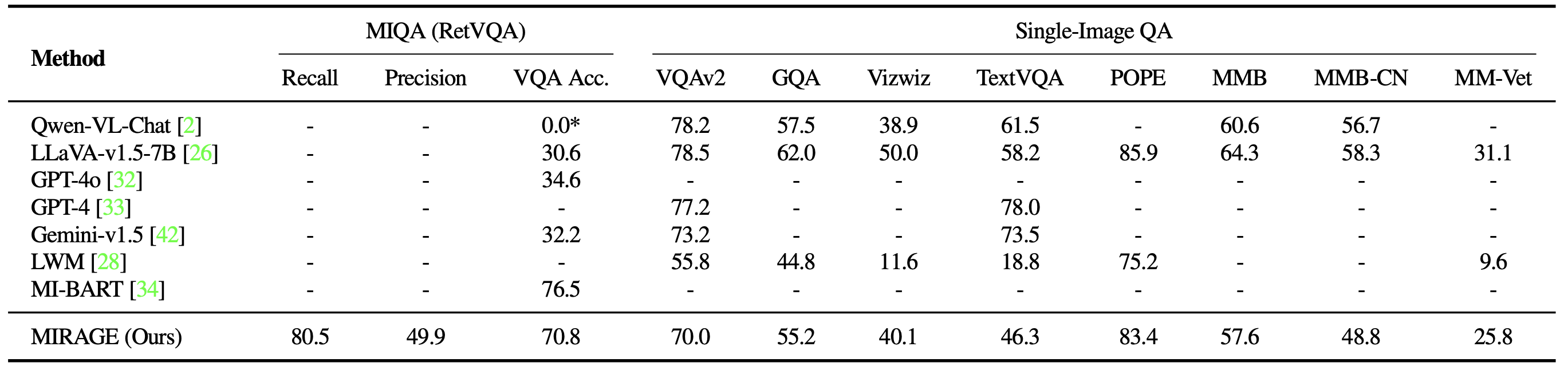
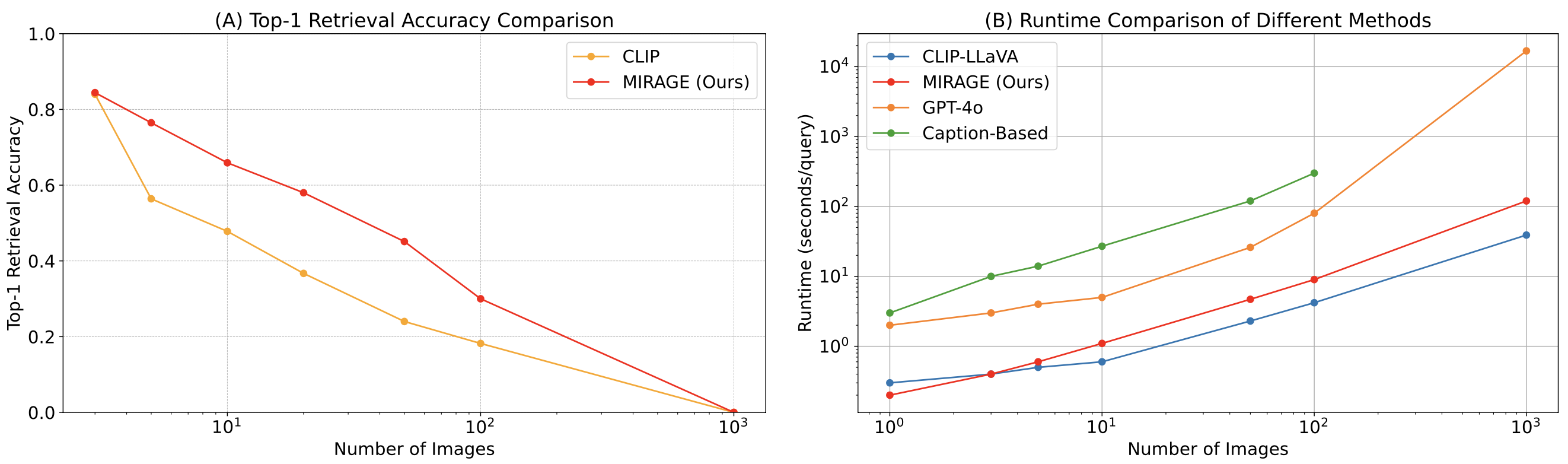
Finalmente, comparamos el perro perdiguero co-entrenado de MIRAGE con ACORTAR. Nuestro recuperador funciona significativamente mejor que CLIP sin perder eficiencia. Esto muestra que, si bien los modelos CLIP pueden ser buenos recuperadores de imágenes de vocabulario abierto, es posible que no funcionen bien cuando se trata de textos tipo pregunta.
En este trabajo, desarrollamos el punto de referencia Visible Haystacks (VH) e identificamos tres deficiencias prevalentes en los grandes modelos multimodales (LMM) existentes:
-
Luchas con los distractores visuales: En tareas con una sola aguja, los LMM muestran una fuerte disminución del rendimiento a medida que aumenta el número de imágenes, lo que indica un desafío importante a la hora de filtrar información visible irrelevante.
-
Dificultad para razonar en varias imágenes: En entornos con múltiples agujas, los enfoques simplistas como los subtítulos seguidos de un management de calidad basado en el lenguaje superan a todos los LMM existentes, lo que resalta la capacidad inadecuada de los LMM para procesar información en múltiples imágenes.
-
Fenómenos en el dominio visible: Tanto los modelos propietarios como los de código abierto muestran sensibilidad a la posición de la información de la aguja dentro de las secuencias de imágenes, exhibiendo un fenómeno de “pérdida en el medio” en el dominio visible.
En respuesta, proponemos MIRAGE, un marco pionero de generador visible recuperador aumentado (visual-RAG). MIRAGE aborda estos desafíos con un innovador compresor de tokens visuales, un recuperador coentrenado y datos de ajuste de instrucciones de múltiples imágenes aumentados.
Después de explorar esta publicación de weblog, alentamos a todos los proyectos LMM futuros a comparar sus modelos utilizando el marco Visible Haystacks para identificar y rectificar posibles deficiencias antes de la implementación. También instamos a la comunidad a explorar la respuesta a preguntas con múltiples imágenes como un medio para avanzar en las fronteras de la verdadera Inteligencia Normal Synthetic (AGI).
Por último, pero no menos importante, consulte nuestra pagina del proyectoy papel arxivy haga clic en el botón de estrella en nuestro repositorio de github!
@article{wu2024visual,
title={Visible Haystacks: Answering More durable Questions About Units of Photos},
creator={Wu, Tsung-Han and Biamby, Giscard and and Quenum, Jerome and Gupta, Ritwik and Gonzalez, Joseph E and Darrell, Trevor and Chan, David M},
journal={arXiv preprint arXiv:2407.13766},
12 months={2024}
}