


{kind=link}
Hoy estamos explorando cómo Ethernet se compara con Infiniband en entornos de IA/ML, centrándonos en cómo Cisco Silicon One™ administra la congestión de la pink y mejora el rendimiento para las cargas de trabajo AI/ML. Esta publicación enfatiza la importancia de la evaluación comparativa y las métricas de KPI en la evaluación de las soluciones de pink, que muestra el clúster Cisco Zeus equipado con 128 GPU NVIDIA® H100 y tecnologías de gestión de congestión de vanguardia como equilibrio de carga dinámica y pulverización de paquetes.
Estándares de pink para satisfacer las necesidades de las cargas de trabajo AI/ML
Las cargas de trabajo de capacitación de IA/ML generan una micro-confongación repetitiva, estresando significativamente los buffers de pink. El tráfico de GPU a GPU de este a oeste durante la capacitación modelo exige un tejido de pink de baja latencia y sin pérdidas. Infiniband ha sido una tecnología dominante en el entorno informático de alto rendimiento (HPC) y recientemente en el entorno AI/ML.
Ethernet es una alternativa madura, con características avanzadas que pueden abordar las rigurosas demandas de las cargas de trabajo de entrenamiento AI/ML y Cisco Silicon, uno puede ejecutar efectivamente el equilibrio de carga y administrar la congestión. Nos propusimos de referencia y comparamos Cisco Silicon One versus Nvidia Spectrum-X ™ e Infiniband.
Evaluación de soluciones de tela de pink para AI/ML
Los patrones de tráfico de pink varían según el tamaño del modelo, la arquitectura y las técnicas de paralelización utilizadas en la capacitación acelerada. Para evaluar las soluciones de tela de pink AI/ML, identificamos los puntos de referencia relevantes y las métricas de indicador de rendimiento clave (KPI) para los equipos de carga de trabajo de IA/ML y de infraestructura, porque ven el rendimiento a través de diferentes lentes.
Establecimos pruebas integrales para medir el rendimiento y generar métricas específicas para los equipos de carga de trabajo e infraestructura de IA/ML. Para estas pruebas, utilizamos el clúster Zeus, con backend y almacenamiento dedicados con una pink de tela cerrada de columna de hoja de 3 etapas estándar, construida con plataformas basadas en Cisco Silicon One y 128 GPU NVIDIA H100. (Ver Figura 1.)

Desarrollamos suites de evaluación comparativa utilizando herramientas estándar de código abierto y estándar de la industria aportadas por Nvidia y otros. Nuestras suites de evaluación comparativa incluyeron las siguientes (ver también la Tabla 1):
- Los puntos de referencia de acceso a la memoria directa remota (RDMA), construidas con las utilidades de IBPerf, para evaluar el rendimiento de la pink durante la congestión creada por Incast
- NVIDIA Collective Communication Library (NCCL) Benchmarks, que evalúan el rendimiento de la aplicación durante la fase de comunicación de capacitación e inferencia entre las GPU
- MlCommons MLPERF Conjunto de puntos de referencia, que evalúa las métricas más comprendidas, el tiempo de finalización del trabajo (JCT) y las fichas por segundo por los equipos de carga de trabajo
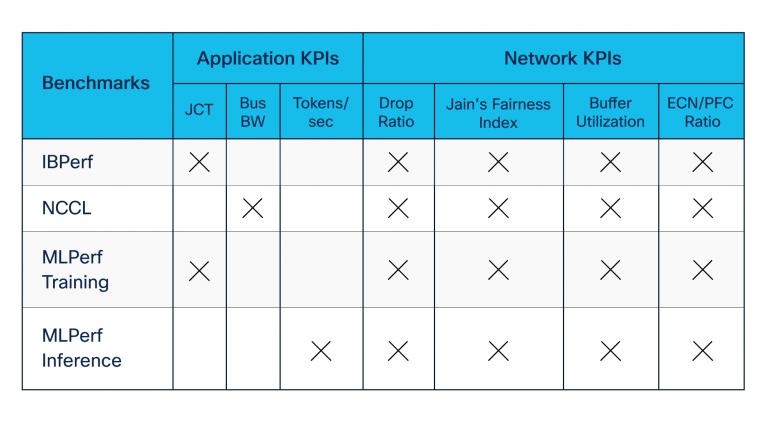
Leyenda:
JCT = Tiempo de finalización del trabajo
Bus bw = ancho de banda del bus
ECN/PFC = Notificación de congestión explícita y management de flujo de prioridad
Benchmarking de NCCL contra las características de evitación de congestión
La congestión se acumula durante la etapa de propagación posterior del proceso de entrenamiento, donde se requiere una sincronización de gradiente entre todas las GPU que participan en la capacitación. A medida que aumenta el tamaño del modelo, también lo hace el tamaño del gradiente y el número de GPU. Esto crea microcongestion masiva en el tejido de la pink. La Figura 2 muestra los resultados de la evaluación comparativa de distribución de tráfico y JCT. Observe cómo Cisco Silicon One admite un conjunto de características avanzadas para evitar la congestión, como el equilibrio de carga dinámica (DLB) y las técnicas de pulverización de paquetes, y la notificación de congestión cuantificada del centro de datos (DCQCN) para la gestión de la congestión.
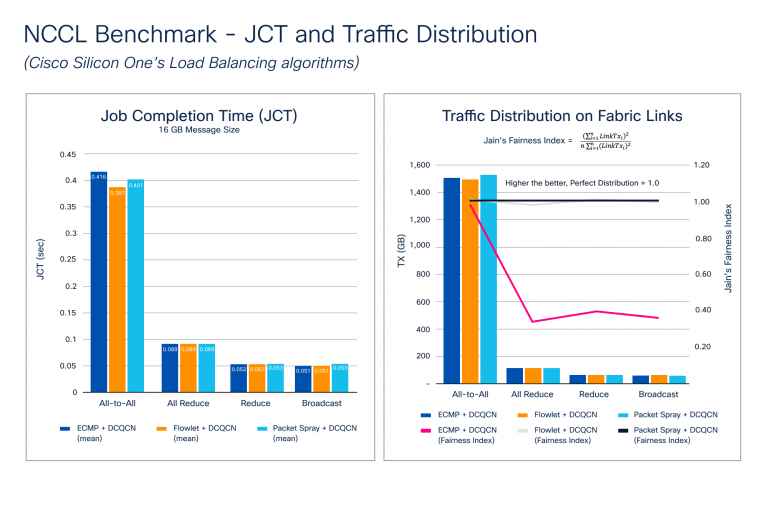
La Figura 2 ilustra cómo los puntos de referencia de NCCL se acumulan con diferentes características de evitación de congestión. Probamos los colectivos más comunes con múltiples tamaños de mensajes diferentes para resaltar estas métricas. Los resultados muestran que JCT mejora con DLB y spray de paquetes para todos, lo que provoca la mayor congestión debido a la naturaleza de la comunicación. Aunque JCT es la métrica más comprendida desde la perspectiva de una aplicación, JCT no muestra cuán efectivamente se utiliza la pink, algo que el equipo de infraestructura necesita saber. Este conocimiento podría ayudarlos a:
- Mejorar la utilización de la pink para mejorar JCT
- Sepa cuántas cargas de trabajo pueden compartir el tejido de la pink sin afectar negativamente a JCT
- Planificar la capacidad a medida que aumenta los casos de uso
Para medir la utilización de la tela de pink, calculamos el índice de equidad de Jain, donde Linktxᵢ es la cantidad de tráfico transmitido en el enlace de la tela:

El valor del índice varía de 0.0 a 1.0, con valores más altos siendo mejores. Un valor de 1.0 representa la distribución perfecta. La distribución de tráfico en la tabla de enlaces de tela en la Figura 2 muestra cómo los algoritmos DLB y Spray de paquetes crean un índice de justicia de Jain casi perfecto, por lo que la distribución de tráfico en la tela de la pink es casi perfecta. ECMP utiliza el hash estático, y dependiendo de la entropía del flujo, puede conducir a la polarización del tráfico, causando microcongestion y afectando negativamente a JCT.
Silicon One versus Nvidia Spectrum-X e Infiniband
El punto de referencia NCCL: el análisis competitivo (Figura 3) muestra cómo Cisco Silicon One se desempeña contra Nvidia Spectrum-X e Infiniband Applied sciences. Los datos de Nvidia fueron tomados de la Publicación de semianálisis. Tenga en cuenta que Cisco no sabe cómo se realizaron estas pruebas, pero sí sabemos que el tamaño del clúster y la conectividad de tela de GPU a la pink es related al clúster Cisco Zeus.
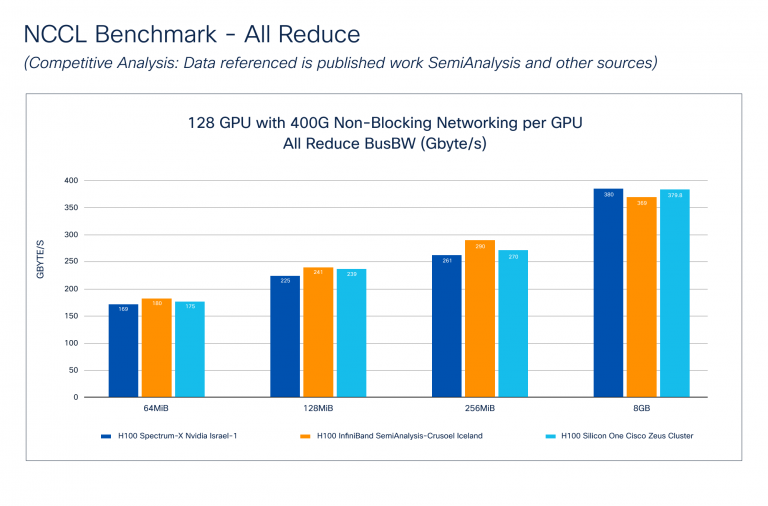
El ancho de banda del bus (Bus BW) de referencia el rendimiento de la comunicación colectiva midiendo la velocidad de las operaciones que involucran múltiples GPU. Cada colectivo tiene una ecuación matemática específica reportada durante la evaluación comparativa. La Figura 3 muestra que Cisco Silicon One: todo Scale back funciona comparablemente con Nvidia Spectrum-X e Infiniband en varios tamaños de mensajes.
Evaluación del rendimiento de la tela de pink
El Benchmark de IBPerf compara el rendimiento de RDMA con el ECMP, DLB y el aerosol de paquetes, que son cruciales para evaluar el rendimiento de la tela de la pink. Los escenarios de incastes, donde múltiples GPU envían datos a una GPU, a menudo causan congestión. Simulamos estas condiciones utilizando herramientas IBPerf.
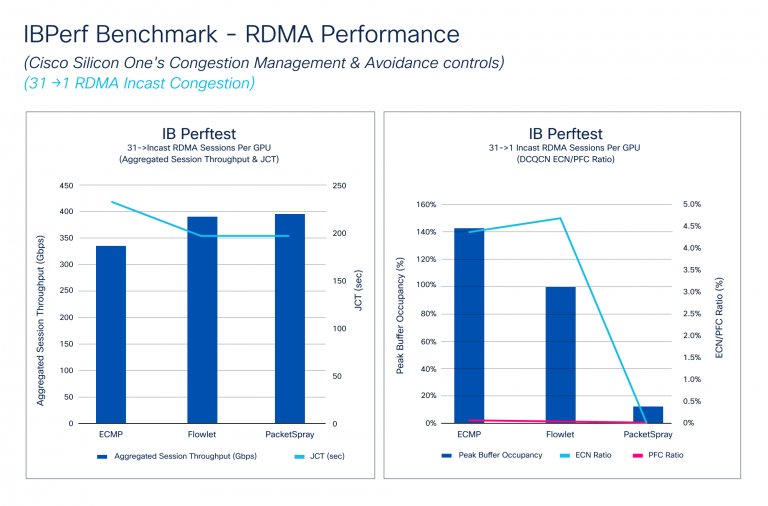
La Figura 4 muestra cómo el rendimiento agregado de la sesión y el JCT responden a diferentes algoritmos de evitación de congestión: ECMP, DLB y spray de paquetes. El ancho de banda de enlace de DLB y Packet Spray Attain, mejorando JCT. También ilustra cómo DCQCN maneja las microconestiones, con las relaciones PFC y ECN mejorando con DLB y caída significativamente con el aerosol de paquetes. Aunque JCT mejora ligeramente de DLB a sprig de paquetes, la relación ECN cae drásticamente debido a la distribución ultimate de tráfico de paquetes spray.
PRENDIDO DE CAPACINA E INFERTA DE INFERENCIA
El punto de referencia de MLPerf – Capacitación e inferencia, publicada por el Organización mlcommonstiene como objetivo permitir una comparación justa de sistemas y soluciones AI/ML.
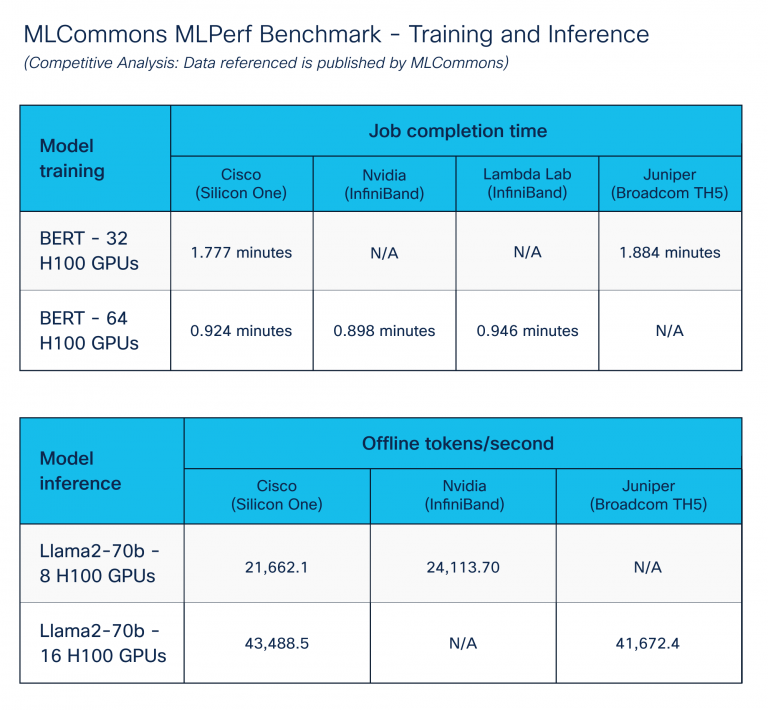
Nos centramos en las soluciones del centro de datos AI/ML ejecutando puntos de referencia de capacitación e inferencia. Para lograr resultados óptimos, nos ajustamos ampliamente a través de componentes de cálculo, almacenamiento y pink utilizando características de gestión de congestión de Cisco Silicon One. La Figura 5 muestra un rendimiento comparable en varios proveedores de plataforma. Cisco Silicon One con Ethernet se desempeña como otras soluciones de proveedores para Ethernet.
Conclusión
Nuestra profunda inmersión en Ethernet e Infiniband dentro de entornos AI/ML destaca la notable destreza de Cisco Silicon One para abordar la congestión y el aumento del rendimiento. Estos avances innovadores muestran la inquebrantable dedicación de Cisco para proporcionar soluciones de redes robustas y de alto rendimiento que satisfacen las rigurosas demandas de las aplicaciones AI/ML de hoy.
Muchas gracias a Vijay Tapaskar, Will Eatherton y Kevin Wollenweber por su apoyo en este proceso de evaluación comparativa.
Discover la infraestructura de IA segura
Descubra la infraestructura AI segura, escalable y de alto rendimiento que necesita desarrollar, implementar y administrar cargas de trabajo de IA de forma segura cuando elija Cisco Safe AI Manufacturing unit con NVIDIA.
Compartir: