


{kind=link}
Estamos entusiasmados de presentar nuestro nuevo modelo de idioma pequeño en el dispositivo, MU. Este modelo aborda escenarios que requieren inferir relaciones complejas de entrada-salida y ha sido diseñado para operar de manera eficiente, ofreciendo un alto rendimiento mientras se ejecuta localmente. Específicamente, este es el modelo de idioma que impulsa el Agente en la configuración,disponible para Home windows Insiders en el canal Dev con Copilot+ PCSal mapear consultas de entrada del lenguaje pure a las llamadas a la función de configuración.
MU está completamente descargado en la Unidad de Procesamiento Neural (NPU) y responde a más de 100 tokens por segundo, cumpliendo con los requisitos de UX exigentes del agente en el escenario de configuración. Este weblog proporcionará más detalles sobre el diseño y la capacitación de MU y cómo fue ajustado para construir el agente en la configuración.
Entrenamiento modelo MU
Habilitador Sílice phi Ejecutar en NPUS nos proporcionó concepts valiosas sobre modelos de ajuste para un rendimiento y eficiencia óptimos. Estos informaron el desarrollo de MU, un modelo de lenguaje de tareas de tamaño micro de tamaño micro diseñado desde cero para funcionar de manera eficiente en los dispositivos NPUS y Edge.
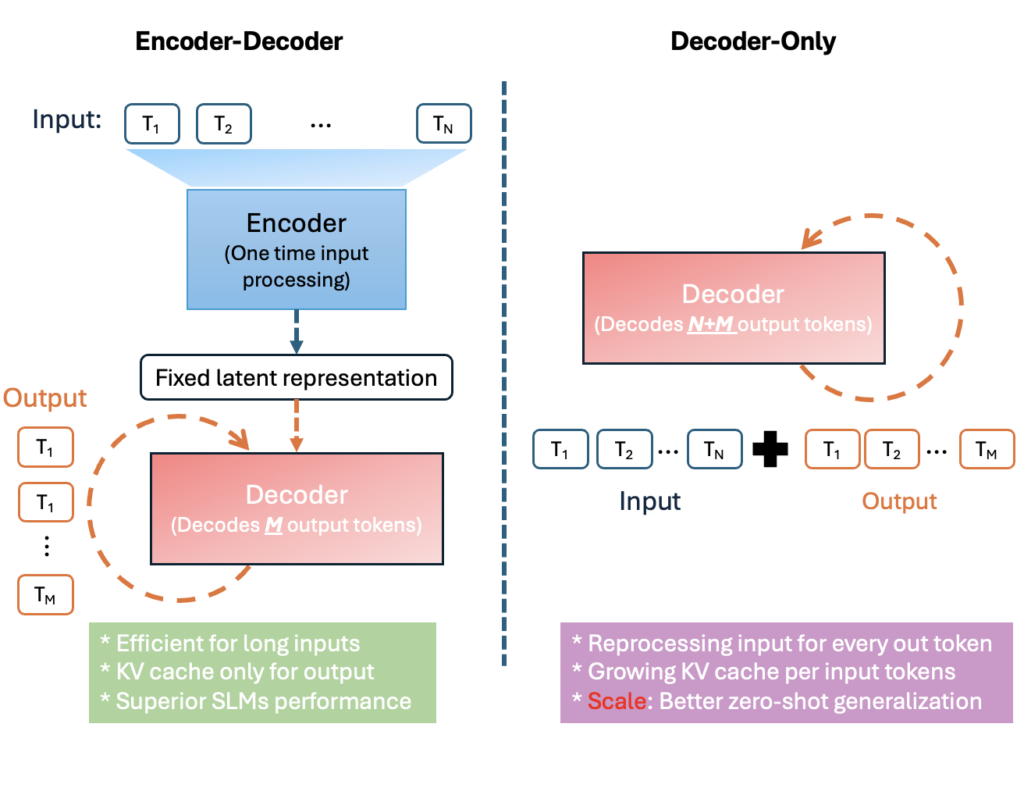
MU es un modelo eficiente de lenguaje codificador-decodificador de 330 m optimizado para la implementación a pequeña escala, particularmente en las NPU en Copilot+ PC. Sigue una arquitectura de codificador -decodificador de transformador, que significa un codificador primero convierte la entrada en una representación latente de longitud fija y un descifrador Luego genera tokens de salida en función de esa representación.
Este diseño produce importantes beneficios de eficiencia. La figura anterior ilustra cómo un codificador codificador reutiliza la representación latente de la entrada, mientras que un decodificador solo debe considerar la secuencia completa de entrada + salida. Al separar los tokens de entrada de los tokens de salida, la codificación única de MU scale back en gran medida el cálculo y la sobrecarga de memoria. En la práctica, esto se traduce en una menor latencia y un mayor rendimiento en {hardware} especializado. Por ejemplo, en una NPU Hexagon de Qualcomm (un acelerador de IA móvil), el enfoque de codificador -decodificador de MU logró sobre 47% de latencia de primera token baja y 4.7 × más alto Velocidad de decodificación en comparación con un modelo de decodificador de tamaño comparable. Estas ganancias son cruciales para aplicaciones en el dispositivo y en tiempo actual.
El diseño de MU fue cuidadosamente sintonizado para las limitaciones y capacidades de las NPU. Esto implicó ajustar la arquitectura del modelo y las formas de parámetros para adaptarse mejor al paralelismo y los límites de memoria del {hardware}. Elegimos dimensiones de capa (como tamaños ocultos y anchos de purple de avance) que se alinean con los tamaños de tensor preferidos de la NPU y las unidades de vectorización, asegurando que las multiplicaciones de matriz y otras operaciones funcionen con una máxima eficiencia. También optimizamos la distribución de parámetros entre el codificador y el decodificador, favoreciendo empíricamente una división 2/3–1/3 (por ejemplo, 32 capas de codificador frente a 12 capas de decodificador en una configuración) para maximizar el rendimiento por parámetro.
Además, MU emplea compartir peso en ciertos componentes para reducir el recuento complete de parámetros. Por ejemplo, vincula los incrustaciones de token de entrada y los incrustaciones de salida, de modo que se usa un conjunto de pesos tanto para representar tokens de entrada como para generar registros de salida. Esto no solo guarda memoria (importante en las NPU de la memoria), sino que también puede mejorar la consistencia entre codificar y decodificar vocabularios.
Finalmente, MU restringe sus operaciones a los operadores optimizados por NPU compatibles con el tiempo de ejecución de implementación. Al evitar cualquier OPS sin apoyo o ineficiente, MU utiliza completamente las capacidades de aceleración de la NPU. Estas optimizaciones conscientes de {hardware} colectivamente hacen que MU sea muy adecuada para la inferencia rápida en el dispositivo.
Rendimiento de embalaje en una décima parte del tamaño
MU agrega tres actualizaciones de transformador clave que aprietas más rendimiento de un modelo más pequeño:
- Twin Layernorm (pre y post-LN) -Normalizar tanto antes como después de cada subcapa mantiene las activaciones bien escala, estabilizando el entrenamiento con una sobrecarga mínima.
- INCREGOS POSICIONALES ROTARIOS (cuerda) -Las rotaciones de valor complejo incrustan las posiciones relativas directamente en la atención, mejorando el razonamiento de contexto largo y permitiendo una extrapolación perfecta a secuencias más largas que las observadas en el entrenamiento.
- Atención agrupada (GQA) – Compartir claves / valores en los grupos de cabeza recorta los parámetros de atención y la memoria al tiempo que preserva la diversidad de la cabeza, scale back la latencia y la alimentación en las NPU.
Se utilizaron técnicas de entrenamiento como los horarios de calentamiento-estable de decaimiento y el optimizador de muones para refinar aún más su rendimiento. Juntas, estas opciones ofrecen una precisión más fuerte y una inferencia más rápida dentro del apretado presupuesto de los dispositivos de borde de MU.
Entrenamos a MU usando GPU A100 en Azure Machine Studying, que tiene lugar en varias fases. Siguiendo las técnicas pioneras primero en el desarrollo de los modelos PHI, comenzamos con la capacitación previa en cientos de miles de millones de tokens educativos de mayor calidad, para aprender sintaxis del lenguaje, gramática, semántica y algunos conocimientos mundiales.
Para continuar mejorando la precisión, el siguiente paso fue la destilación de Modelos PHI de Microsoft. Al capturar algunos de los conocimientos de la PHI, los modelos MU logran una notable eficiencia de parámetros. Todo esto produce un modelo base que se adapta bien a una variedad de tareas, pero el emparejamiento con datos específicos de tareas junto con el ajuste fino adicional a través de métodos de adaptación de bajo rango (LORA), puede mejorar dramáticamente el rendimiento del modelo.
Evaluamos la precisión de MU ajustando varias tareas, incluidas EQUIPO, CodExglue y agente de configuración de Home windows (del cual hablaremos más más adelante en este weblog). Para muchas tareas, el MU específico de la tarea logra un rendimiento notable a pesar de su tamaño micro de unos pocos cientos de millones de parámetros.
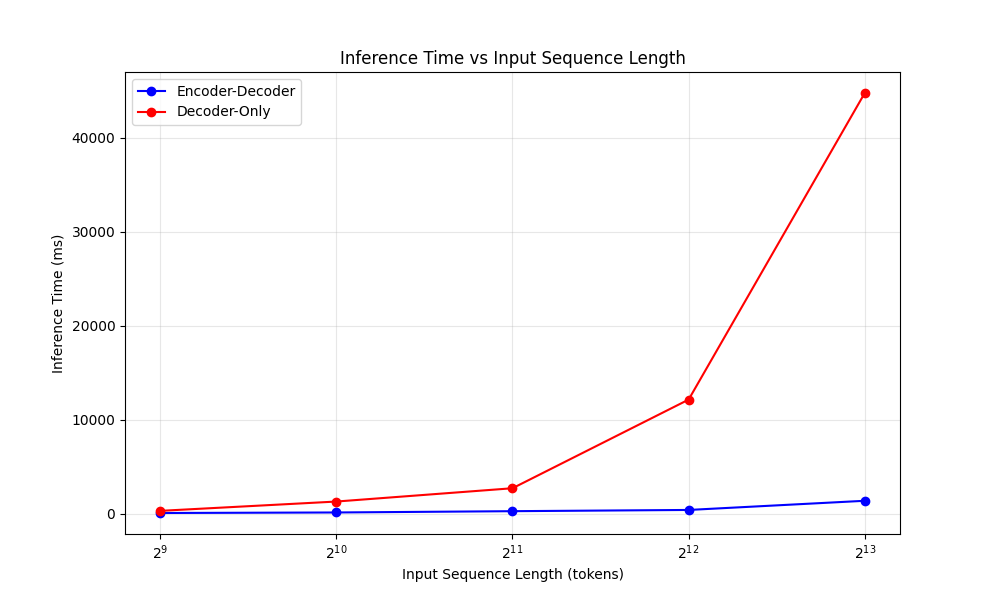
Al comparar MU con un Phi-3.5-Mini afligido similarmente fino, encontramos que MU es casi comparable en rendimiento a pesar de ser una décima parte del tamaño, capaz de manejar decenas de miles de longitudes de contexto de entrada y más de cien tokens de salida por segundo.
| Tarea Modelo | Mu sintonizado | Phi sintonizado |
| EQUIPO | 0.692 | 0.846 |
| CodExglue | 0.934 | 0.930 |
| Agente de configuración | 0.738 | 0.815 |
Cuantización del modelo y optimización del modelo
Para permitir que el modelo MU ejecute eficientemente en el dispositivo, aplicamos técnicas de cuantización del modelo avanzado adaptadas a NPUS en copilot+ PC.
Utilizamos cuantización posterior al entrenamiento (PTQ) para convertir los pesos del modelo y las activaciones desde el punto flotante hasta las representaciones enteras, principalmente de 8 bits y 16 bits. PTQ nos permitió tomar un modelo totalmente capacitado y cuantificarlo sin requerir reentrenamiento, acelerar significativamente nuestra línea de tiempo de implementación y optimizar para ejecutar eficientemente en dispositivos Copilot+. En última instancia, este enfoque conservó la precisión del modelo al tiempo que scale back drásticamente la huella de la memoria y calcula los requisitos sin afectar la experiencia del usuario.
La cuantización fue solo una parte de la tubería de optimización. También colaboramos estrechamente con nuestros Silicon Companions en AMD, Intel y Qualcomm para garantizar que las operaciones cuantificadas cuando se ejecuten MU estuvieran completamente optimizadas para las NPU objetivo. Esto incluyó ajustar a los operadores matemáticos, alinearse con los patrones de ejecución específicos de {hardware} y validar el rendimiento en diferentes silicones. Los pasos de optimización dan como resultado inferencias altamente eficientes en dispositivos de borde, produciendo salidas en más de 200 tokens/segundo en una computadora portátil de superficie 7.
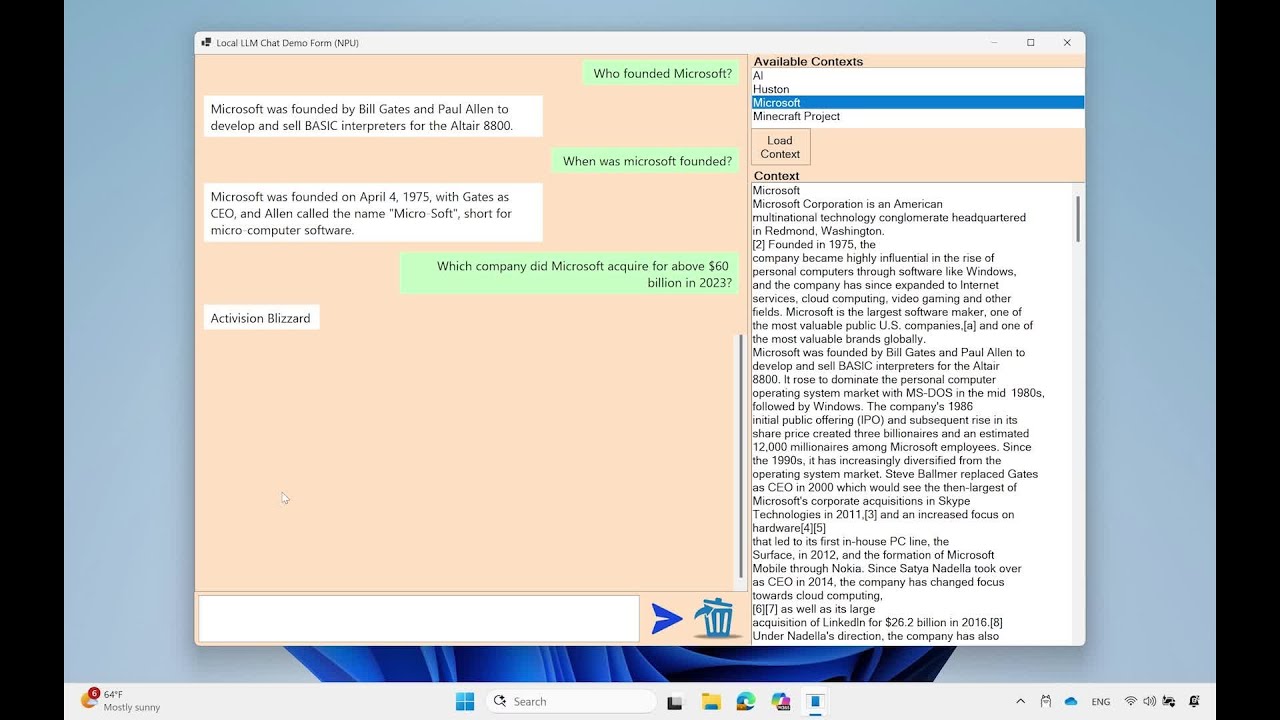
MU Ejecutando una tarea de preguntas en un dispositivo Edge, utilizando un contexto procedente de Wikipedia: (https://en.wikipedia.org/wiki/microsoft)
Observe los rendimientos de token rápidos y el tiempo extremely rápido hasta las primeras respuestas de token a pesar de la gran cantidad de contexto de entrada proporcionado al modelo.
Al combinar técnicas de cuantización de vanguardia con optimizaciones específicas de {hardware}, nos aseguramos de que MU sea altamente efectivo para las implementaciones del mundo actual en aplicaciones limitadas por recursos. En la siguiente sección, entramos en detalles sobre cómo MU fue ajustado y aplicado para construir el nuevo agente de Home windows en Configuración en Copilot+ PCS.
Modelo ajustando al agente en la configuración
Para mejorar la facilidad de uso de Home windows, nos centramos en abordar el desafío de cambiar cientos de configuraciones del sistema. Nuestro objetivo period crear un agente con IA dentro de la configuración que comprenda el lenguaje pure y cambie la configuración no dañada relevante sin problemas. Nuestro objetivo fue integrar este agente en el cuadro de búsqueda existente para una experiencia de usuario fluida, que requiere una latencia extremely baja para numerosas configuraciones posibles. Después de probar varios modelos, Phi Lora inicialmente cumplió objetivos de precisión, pero period demasiado grande para cumplir con los objetivos de latencia. MU, con las características correctas, se requiere un ajuste específico de la tarea para un rendimiento óptimo en la configuración de Home windows.
Si bien la línea de base en este escenario se destacó en términos de rendimiento y huella de energía, incurrió en una caída de precisión de 2X usando los mismos datos sin ningún ajuste. Para cerrar la brecha, escalamos el entrenamiento a muestras de 3.6m (1300x) y expandimos de aproximadamente 50 configuraciones a cientos de configuraciones. Al emplear enfoques sintéticos para el etiquetado automatizado, el ajuste rápido con metadatos, fraseo diverso, inyección de ruido y muestreo inteligente, el agente de MUS de MU utilizado para el Agente de configuración cumplió con éxito nuestros objetivos de calidad. El modelo MU MODS logró tiempos de respuesta de menos de 500 milisegundos, alineándose con nuestros objetivos para un agente receptivo y confiable en entornos que ampliaron a cientos de entornos. La imagen a continuación muestra cómo la experiencia se integra con un ejemplo que muestra la asignación de una consulta de lenguaje de uso pure a una acción de configuración que la interfaz de interfaz de usuario aparece.
Para abordar aún más el desafío de consultas de usuarios cortas y ambiguas, seleccionamos un conjunto de evaluación diverso que combina entradas reales de los usuarios, consultas sintéticas y configuraciones comunes, asegurando que el modelo pueda manejar una amplia gama de escenarios de manera efectiva. Observamos que el modelo funcionó mejor en consultas de múltiples palabras que transmitieron una intención clara, en oposición a las entradas de palabras cortas o parciales, que a menudo carecen de contexto suficiente para una interpretación precisa. Para abordar esta brecha, el agente en la configuración se integra en el cuadro de búsqueda de configuración, lo que permite consultas cortas que no cumplen con el umbral de múltiples palabras para continuar con los resultados de búsqueda léxica y semántica en el cuadro de búsqueda, al tiempo que permite que las consultas de múltiples palabras surjan el agente para devolver las respuestas accionables de alta precisión.
Administrar la extensa gama de configuraciones de Home windows planteó sus propios desafíos, particularmente con funcionalidades superpuestas. Por ejemplo, incluso una consulta easy como “aumentar el brillo” podría referirse a múltiples cambios de configuración: si un usuario tiene monitores duales, ¿eso significa aumentar el brillo al monitor primario o un monitor secundario?
Para abordar esto, refinamos nuestros datos de capacitación para priorizar la configuración más utilizada a medida que continuamos refinando la experiencia para tareas más complejas.
Que esta por delante
Agradecemos los comentarios de los usuarios en el programa de Insiders de Home windows a medida que continuamos refinando la experiencia del agente en la configuración.
As we have shared in our earlier blogs, these breakthroughs would not be potential with out the help of efforts from the Utilized Science Group and our associate groups in WAIIA and WinData that contributed to this work, together with: Adrian Bazaga, Archana Ramesh, Carol Ke, Chad Voegele, Cong Li, Daniel Rings, David Kolb, Eric Carter, Eric Sommerlade, Ivan Razumenic, Jana Shen, John Jansen, Joshua Elsdon, Karthik Sudandraprakash, Karthik Vijayan, Kevin Zhang, Leon Xu, Madhvi Mishra, Mathew Salvaris, Milos Petkovic, Patrick Derks, Prateek Punj, Rui Liu, Sunando Senguupta, Tamara Turnadzic, Teo Sarkic, Tingyu, Tingyu, Xiay, Xiay, Xiay, Xiay, Xiay, Xiay. Yuchao Dai.