


{kind=link}

Los investigadores del MIT desarrollaron una técnica de inteligencia synthetic que permite a un robotic desarrollar planes complejos para manipular un objeto utilizando toda su mano, no solo las yemas de los dedos. Este modelo puede generar planes efectivos en aproximadamente un minuto usando una computadora portátil estándar. Aquí, un robotic intenta girar un cubo 180 grados. Imagen: Cortesía de los investigadores.
Por Adam Zewe | Noticias del MIT
Imagina que quieres subir una caja grande y pesada por un tramo de escaleras. Puedes extender los dedos y levantar la caja con ambas manos, luego sostenerla sobre tus antebrazos y equilibrarla contra tu pecho, usando todo tu cuerpo para manipular la caja.
Los humanos generalmente son buenos manipulando todo el cuerpo, pero los robots tienen dificultades con esas tareas. Para el robotic, cada punto donde la caja podría tocar cualquier punto de los dedos, brazos y torso del portador representa un evento de contacto sobre el cual debe razonar. Con miles de millones de eventos de contacto potenciales, la planificación de esta tarea rápidamente se vuelve intratable.
Ahora Investigadores del MIT encontraron una manera de simplificar este procesoconocido como planificación de manipulación rica en contactos. Utilizan una técnica de IA llamada suavizado, que resume muchos eventos de contacto en un número menor de decisiones, para permitir que incluso un algoritmo easy identifique rápidamente un plan de manipulación efectivo para el robotic.
Aunque todavía está en sus inicios, este método podría permitir a las fábricas utilizar robots móviles más pequeños que puedan manipular objetos con todo su brazo o cuerpo, en lugar de grandes brazos robóticos que sólo pueden agarrar con las yemas de los dedos. Esto puede ayudar a reducir el consumo de energía y reducir los costos. Además, esta técnica podría ser útil en robots enviados en misiones de exploración a Marte u otros cuerpos del sistema photo voltaic, ya que podrían adaptarse rápidamente al entorno utilizando únicamente un ordenador a bordo.
“En lugar de pensar en esto como un sistema de caja negra, si podemos aprovechar la estructura de este tipo de sistemas robóticos usando modelos, existe la oportunidad de acelerar todo el procedimiento para intentar tomar estas decisiones y generar soluciones ricas en contactos. planes”, cube HJ Terry Suhestudiante de posgrado en ingeniería eléctrica e informática (EECS) y coautor principal de un papel sobre esta técnica.
Junto a Suh en el artículo se encuentran el coautor principal Tao Pang PhD ’23, robótico del Boston Dynamics AI Institute; Lujie Yang, estudiante de posgrado de EECS; y autor principal Russ TedrakeProfesor Toyota de EECS, Aeronáutica y Astronáutica e Ingeniería Mecánica, y miembro del Laboratorio de Informática e Inteligencia Synthetic (CSAIL). La investigación aparece esta semana en Transacciones IEEE sobre robótica.
Aprendiendo sobre el aprendizaje
El aprendizaje por refuerzo es una técnica de aprendizaje automático en la que un agente, como un robotic, aprende a completar una tarea mediante prueba y error con una recompensa por acercarse a una meta. Los investigadores dicen que este tipo de aprendizaje requiere un enfoque de caja negra porque el sistema debe aprender todo sobre el mundo mediante prueba y error.
Se ha utilizado eficazmente para la planificación de manipulación rica en contactos, donde el robotic busca aprender la mejor manera de mover un objeto de una manera específica.
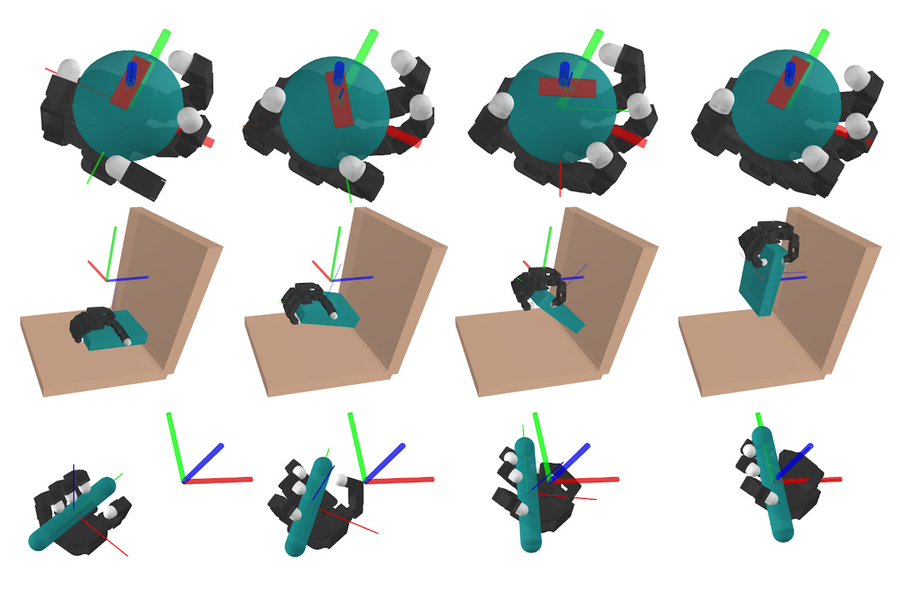
En estas figuras, un robotic simulado realiza tres tareas de manipulación ricas en contacto: manipulación handbook de una pelota, levantar un plato y manipular un bolígrafo en una orientación específica. Imagen: Cortesía de los investigadores.
Pero debido a que puede haber miles de millones de puntos de contacto potenciales sobre los cuales un robotic debe razonar al determinar cómo usar sus dedos, manos, brazos y cuerpo para interactuar con un objeto, este enfoque de prueba y error requiere una gran cantidad de cálculos.
“El aprendizaje por refuerzo puede necesitar pasar millones de años en tiempo de simulación para poder realmente aprender una política”, añade Suh.
Por otro lado, si los investigadores diseñan específicamente un modelo basado en la física utilizando su conocimiento del sistema y la tarea que quieren que realice el robotic, ese modelo incorpora una estructura sobre este mundo que lo hace más eficiente.
Sin embargo, los enfoques basados en la física no son tan efectivos como el aprendizaje por refuerzo cuando se trata de planificación de manipulación rica en contactos; Suh y Pang se preguntaron por qué.
Realizaron un análisis detallado y descubrieron que una técnica conocida como suavizado permite que el aprendizaje por refuerzo funcione tan bien.
Muchas de las decisiones que un robotic podría tomar al determinar cómo manipular un objeto no son importantes en el gran esquema de las cosas. Por ejemplo, cada ajuste infinitesimal de un dedo, ya sea que entre en contacto o no con el objeto, no importa mucho. Los promedios suavizados eliminan muchas de esas decisiones intermedias y sin importancia, dejando algunas importantes.
El aprendizaje por refuerzo realiza el suavizado implícitamente probando muchos puntos de contacto y luego calculando un promedio ponderado de los resultados. Basándose en esta información, los investigadores del MIT diseñaron un modelo easy que realiza un tipo comparable de suavizado, lo que le permite centrarse en las interacciones centrales entre robotic y objeto y predecir el comportamiento a largo plazo. Demostraron que este enfoque podría ser tan eficaz como el aprendizaje por refuerzo para generar planes complejos.
“Si sabes un poco más sobre tu problema, puedes diseñar algoritmos más eficientes”, afirma Pang.
Una combinación ganadora
Aunque suavizar simplifica enormemente las decisiones, buscar entre las decisiones restantes todavía puede ser un problema difícil. Entonces, los investigadores combinaron su modelo con un algoritmo que puede buscar rápida y eficientemente todas las decisiones posibles que el robotic podría tomar.
Con esta combinación, el tiempo de cálculo se redujo a aproximadamente un minuto en una computadora portátil estándar.
Primero probaron su enfoque en simulaciones en las que a manos robóticas se les asignaban tareas como mover un bolígrafo a una configuración deseada, abrir una puerta o recoger un plato. En cada caso, su enfoque basado en modelos logró el mismo rendimiento que el aprendizaje por refuerzo, pero en una fracción del tiempo. Vieron resultados similares cuando probaron su modelo en {hardware} en brazos robóticos reales.
“Las mismas concepts que permiten la manipulación de todo el cuerpo también funcionan para la planificación con manos diestras y humanas. Anteriormente, la mayoría de los investigadores decían que el aprendizaje por refuerzo period el único enfoque que se adaptaba a manos diestras, pero Terry y Tao demostraron que al tomar esta concept clave de suavizado (aleatorizado) del aprendizaje por refuerzo, pueden hacer que los métodos de planificación más tradicionales también funcionen extremadamente bien. ”, cube Tedrake.
Sin embargo, el modelo que desarrollaron se basa en una aproximación más easy del mundo actual, por lo que no puede manejar movimientos muy dinámicos, como la caída de objetos. Si bien es eficaz para tareas de manipulación más lentas, su enfoque no puede crear un plan que permita a un robotic tirar una lata a un contenedor de basura, por ejemplo. En el futuro, los investigadores planean mejorar su técnica para poder abordar estos movimientos altamente dinámicos.
“Si estudias tus modelos detenidamente y comprendes realmente el problema que intentas resolver, definitivamente hay algunos beneficios que puedes lograr. Hay beneficios al hacer cosas que van más allá de la caja negra”, cube Suh.
Este trabajo está financiado, en parte, por Amazon, el Laboratorio Lincoln del MIT, la Fundación Nacional de Ciencias y el Grupo Ocado.

Noticias del MIT