


{kind=link}

Ejemplos de respuestas de modelos lingüísticos a diferentes variedades de inglés y reacciones de hablantes nativos.
ChatGPT funciona increíblemente bien comunicándose con personas en inglés. ¿Pero el inglés de quién?
Sólo el 15% de los usuarios de ChatGPT son de EE. UU., donde el inglés americano estándar es el predeterminado. Pero el modelo también se usa comúnmente en países y comunidades donde la gente habla otras variedades de inglés. Más de mil millones de personas en todo el mundo hablan variedades como el inglés indio, el inglés nigeriano, el inglés irlandés y el inglés afroamericano.
Los hablantes de estas variedades no “estándar” a menudo enfrentan discriminación en el mundo actual. Les han dicho que su forma de hablar es no profesional o incorrecto, desacreditados como testigosy vivienda denegada-a pesar de extenso investigación lo que indica que todas las variedades lingüísticas son igualmente complejas y legítimas. Discriminar la forma en que alguien habla suele equivaler a discriminar por su raza, etnia o nacionalidad. ¿Qué pasa si ChatGPT exacerba esta discriminación?
Para responder a esta pregunta, nuestro artículo reciente examina cómo cambia el comportamiento de ChatGPT en respuesta al texto en diferentes variedades de inglés. Descubrimos que las respuestas de ChatGPT exhiben sesgos consistentes y generalizados contra las variedades no “estándar”, incluido un aumento de estereotipos y contenido degradante, peor comprensión y respuestas condescendientes.
Nuestro estudio
Proporcionamos a GPT-3.5 Turbo y GPT-4 texto en diez variedades de inglés: dos variedades “estándar”, inglés americano estándar (SAE) e inglés británico estándar (SBE); y ocho variedades no “estándar”: inglés afroamericano, indio, irlandés, jamaicano, keniano, nigeriano, escocés y singapurense. Luego, comparamos las respuestas del modelo de lenguaje con las variedades “estándar” y las variedades no “estándar”.
Primero, queríamos saber si las características lingüísticas de una variedad que están presentes en el mensaje se conservarían en las respuestas de GPT-3.5 Turbo a ese mensaje. Anotamos las indicaciones y las respuestas modelo para las características lingüísticas de cada variedad y si usaban ortografía estadounidense o británica (por ejemplo, “coloration” o “práctica”). Esto nos ayuda a comprender cuándo ChatGPT imita o no una variedad y qué factores pueden influir en el grado de imitación.
Luego, hicimos que hablantes nativos de cada una de las variedades calificaran las respuestas del modelo según diferentes cualidades, tanto positivas (como calidez, comprensión y naturalidad) como negativas (como estereotipos, contenido degradante o condescendencia). Aquí incluimos las respuestas originales de GPT-3.5, además de respuestas de GPT-3.5 y GPT-4 donde se les pidió a los modelos que imitaran el estilo de la entrada.
Resultados
Esperábamos que ChatGPT produjera inglés americano estándar de forma predeterminada: el modelo se desarrolló en los EE. UU. y el inglés americano estándar es probablemente la variedad mejor representada en sus datos de entrenamiento. De hecho, encontramos que las respuestas del modelo conservan características del SAE mucho más que cualquier dialecto no “estándar” (por un margen de más del 60%). Pero, sorprendentemente, el modelo hace Imita otras variedades de inglés, aunque no de manera consistente. De hecho, imita variedades con más hablantes (como el inglés nigeriano e indio) con más frecuencia que variedades con menos hablantes (como el inglés jamaicano). Eso sugiere que la composición de los datos de entrenamiento influye en las respuestas a dialectos no “estándar”.
ChatGPT también respeta las convenciones estadounidenses de manera predeterminada, lo que podría frustrar a los usuarios no estadounidenses. Por ejemplo, las respuestas del modelo a entradas con ortografía británica (la predeterminada en la mayoría de los países no estadounidenses) casi universalmente vuelven a la ortografía estadounidense. Esa es una fracción sustancial de la base de usuarios de ChatGPT probablemente obstaculizada por la negativa de ChatGPT a adaptarse a las convenciones de escritura locales.
Las respuestas de los modelos están sistemáticamente sesgadas en contra de las variedades no “estándar”. Las respuestas predeterminadas de GPT-3.5 a variedades no “estándar” exhiben consistentemente una variedad de problemas: estereotipos (19% peor que para las variedades “estándar”), contenido degradante (25% peor), falta de comprensión (9% peor) y respuestas condescendientes (15% peor).
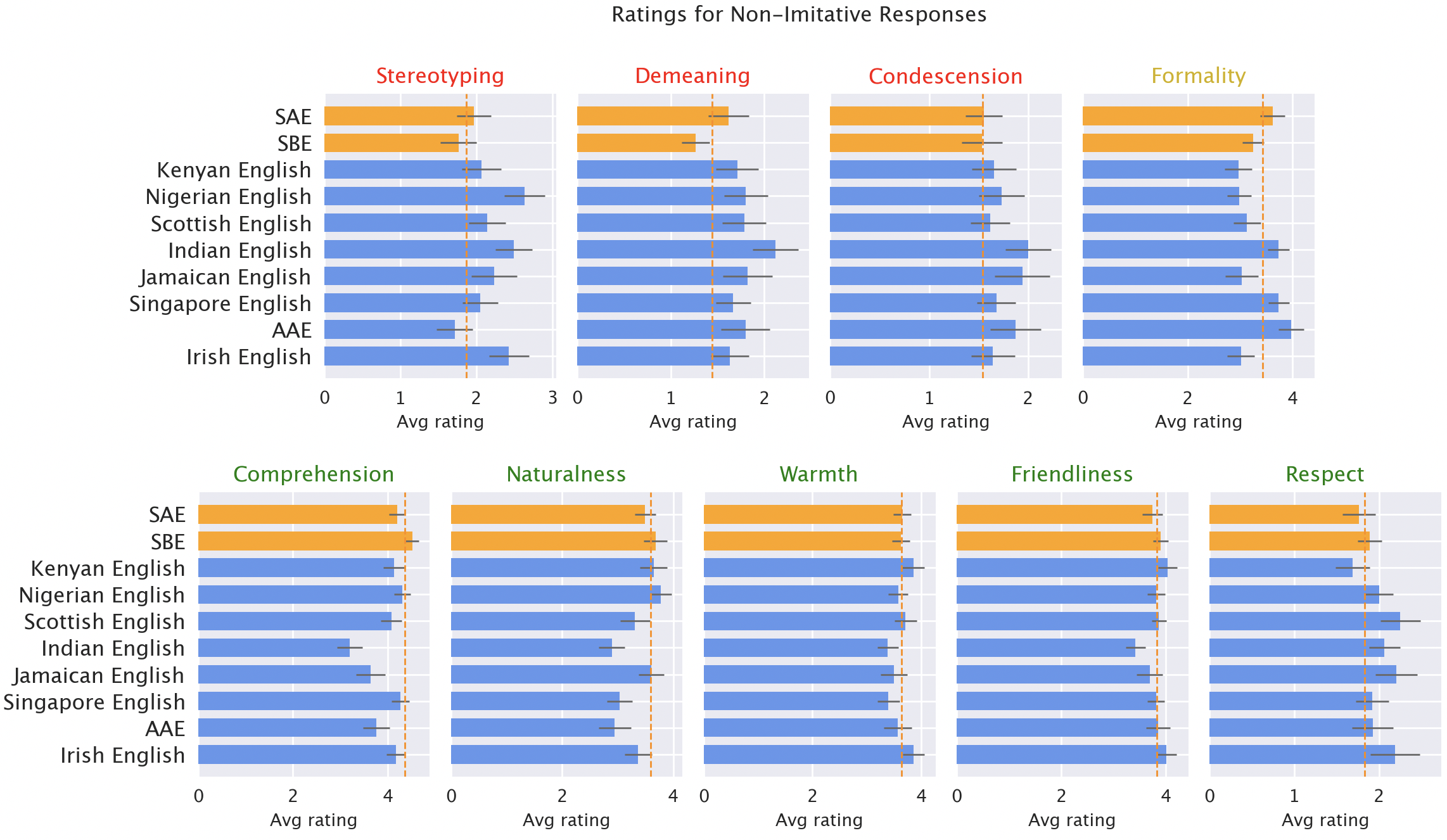
Calificaciones de hablantes nativos de respuestas modelo. Las respuestas a las variedades no “estándar” (azul) fueron calificadas como peores que las respuestas a las variedades “estándar” (naranja) en términos de estereotipos (19 % peor), contenido degradante (25 % peor), comprensión (9 % peor), naturalidad (8% peor) y condescendencia (15% peor).
Cuando se le pide a GPT-3.5 que imite el dialecto de entrada, las respuestas exacerban el contenido estereotipado (9% peor) y la falta de comprensión (6% peor). GPT-4 es un modelo más nuevo y potente que GPT-3.5, por lo que esperamos que mejore con respecto a GPT-3.5. Pero aunque las respuestas de GPT-4 que imitan la entrada mejoran las de GPT-3.5 en términos de calidez, comprensión y amabilidad, exacerban los estereotipos (un 14% peor que GPT-3.5 para las variedades minorizadas). Esto sugiere que los modelos más nuevos y más amplios no resuelven automáticamente la discriminación dialectal: de hecho, podrían empeorarla.
Trascendencia
ChatGPT puede perpetuar la discriminación lingüística hacia hablantes de variedades no “estándar”. Si estos usuarios tienen problemas para que ChatGPT los comprenda, les resultará más difícil utilizar estas herramientas. Esto puede reforzar las barreras contra los hablantes de variedades no “estándar” a medida que los modelos de IA se utilizan cada vez más en la vida diaria.
Además, los estereotipos y las respuestas degradantes perpetúan la thought de que los hablantes de variedades no “estándar” hablan menos correctamente y merecen menos respeto. A medida que el uso de modelos lingüísticos aumenta a nivel mundial, estas herramientas corren el riesgo de reforzar las dinámicas de poder y amplificar las desigualdades que perjudican a las comunidades lingüísticas minoritarias.
Obtenga más información aquí: [ paper ]