


{kind=link}
El concepto de robots que cambian de forma se presentó al mundo en 1991, cuando el T-1000 apareció en la película de culto. Terminator 2: El día del juicio closing. Desde entonces (si no antes), muchos científicos han soñado con crear un robotic con la capacidad de cambiar de forma para realizar diversas tareas.
Y, de hecho, estamos empezando a ver que algunas de estas cosas cobran vida, como esta “excremento magnético” de la Universidad China de Hong Kongpor ejemplo, o este hombre de lego de metallic líquidocapaz de fundirse y reformarse para escapar de la cárcel. Sin embargo, ambos requieren controles magnéticos externos. No pueden moverse de forma independiente.
Pero un equipo de investigación del MIT está trabajando en el desarrollo de otros que sí puedan hacerlo. Han desarrollado una técnica de aprendizaje automático que entrena y controla un robotic ‘limo’ reconfigurable que se aplasta, se dobla y se alarga para interactuar con su entorno y objetos externos. Nota al margen decepcionante: el robotic no está hecho de metallic líquido.
Clip de TERMINATOR 2: EL DÍA DEL JUICIO – “Escape del hospital” (1991)
“Cuando la gente piensa en robots blandos, tiende a pensar en robots que son elásticos, pero que vuelven a su forma unique”, dijo Boyuan Chen, del Laboratorio de Ciencias de la Computación e Inteligencia Synthetic (CSAIL) del MIT y coautor del estudio que describe la el trabajo de los investigadores. “Nuestro robotic es como un limo y, de hecho, puede cambiar su morfología. Es muy sorprendente que nuestro método haya funcionado tan bien porque estamos ante algo muy nuevo”.
Los investigadores tuvieron que idear una forma de controlar un robotic limo que no tuviera brazos, piernas o dedos – o incluso cualquier tipo de esqueleto contra el cual sus músculos puedan empujar y tirar – o incluso cualquier ubicación establecida para cualquiera de sus actuadores musculares. Una forma tan informe y un sistema tan infinitamente dinámico… Todo esto presenta un escenario de pesadilla: ¿cómo se supone que se pueden programar los movimientos de un robotic así?
Claramente, cualquier tipo de esquema de management estándar sería inútil en este escenario, por lo que el equipo recurrió a la IA, aprovechando su inmensa capacidad para manejar datos complejos. Y desarrollaron un algoritmo de management que aprende cómo mover, estirar y dar forma a dicho robotic, a veces varias veces, para completar una tarea en specific.

MIT
El aprendizaje por refuerzo es una técnica de aprendizaje automático que entrena al software program para tomar decisiones mediante prueba y error. Es excelente para entrenar robots con partes móviles bien definidas, como una pinza con “dedos”, que pueden ser recompensados por acciones que los acerquen a una meta, por ejemplo, recoger un huevo. ¿Pero qué pasa con un informe? robotic blando que está controlado por campos magnéticos?
“Un robotic así podría tener miles de pequeños trozos de músculo que controlar”, dijo Chen. “Por eso es muy difícil aprender de la manera tradicional”.
Un robotic de limo requiere que se muevan grandes trozos a la vez para lograr un cambio de forma funcional y efectivo; manipular partículas individuales no daría como resultado el cambio sustancial requerido. Entonces, los investigadores utilizaron el aprendizaje por refuerzo de una manera no tradicional.
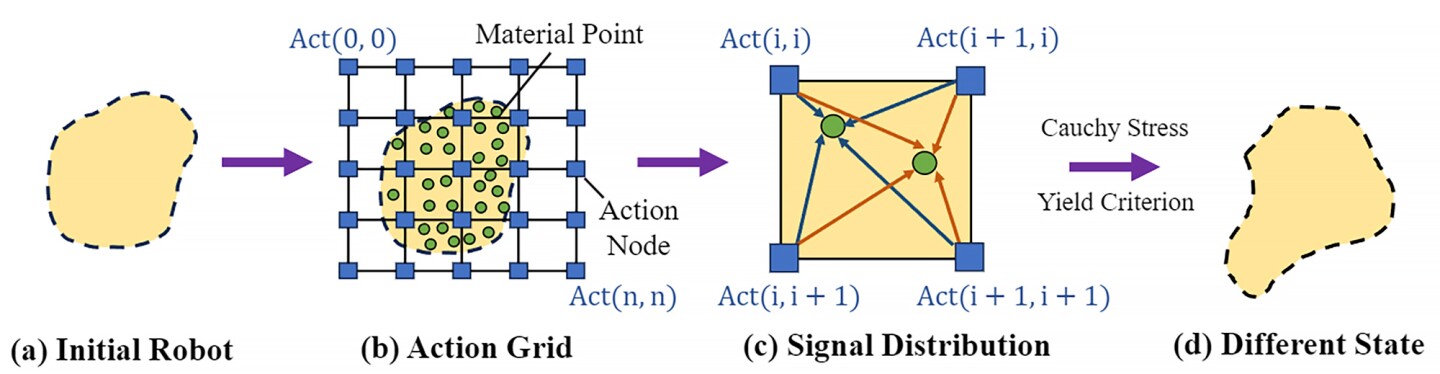
Huang et al.
En el aprendizaje por refuerzo, el conjunto de todas las acciones u opciones válidas disponibles para un agente cuando interactúa con un entorno se denomina “espacio de acción”. Aquí, el espacio de acción del robotic fue tratado como una imagen compuesta de píxeles. Su modelo utilizó imágenes del entorno del robotic para generar un espacio de acción 2D cubierto por puntos superpuestos con una cuadrícula.
De la misma manera que se relacionan los píxeles cercanos en una imagen, el algoritmo de los investigadores entendió que los puntos de acción cercanos tenían correlaciones más fuertes. Por lo tanto, los puntos de acción alrededor del “brazo” del robotic se moverán juntos cuando cambie de forma; Los puntos de acción de la “pierna” también se moverán juntos, pero de forma diferente al movimiento del brazo.
Los investigadores también desarrollaron un algoritmo con “aprendizaje de políticas de grueso a fino”. En primer lugar, el algoritmo se entrena utilizando una política aproximada de baja resolución (es decir, moviendo grandes fragmentos) para explorar el espacio de acción e identificar patrones de acción significativos. Luego, una política fina de mayor resolución profundiza para optimizar las acciones del robotic y mejorar su capacidad para realizar tareas complejas.

MIT
“De grueso a fino significa que cuando se realiza una acción aleatoria, es possible que esa acción aleatoria marque la diferencia”, dijo Vincent Sitzmann, coautor del estudio que también es de CSAIL. “El cambio en el resultado probablemente sea muy significativo porque controlas de forma aproximada varios músculos al mismo tiempo”.
Lo siguiente fue probar su enfoque. Crearon un entorno de simulación llamado DittoGym, que presenta ocho tareas que evalúan la capacidad de un robotic reconfigurable para cambiar de forma. Por ejemplo, hacer que el robotic haga coincidir una letra o un símbolo y hacerlo crecer, cavar, patear, atrapar y correr.
Esquema de management del robotic limo del MIT: ejemplos
“Nuestra selección de tareas en DittoGym sigue tanto los principios de diseño de referencia de aprendizaje por refuerzo genérico como las necesidades específicas de los robots reconfigurables”, dijo Suning Huang del Departamento de Automatización de la Universidad de Tsinghua, China, investigador visitante en el MIT y coautor del estudio.
“Cada tarea está diseñada para representar ciertas propiedades que consideramos importantes, como la capacidad de navegar a través de exploraciones de largo horizonte, la capacidad de analizar el entorno e interactuar con objetos externos”, continuó Huang. “Creemos que juntas pueden dar usuarios una comprensión integral de la flexibilidad de los robots reconfigurables y la efectividad de nuestro esquema de aprendizaje por refuerzo”.
Ídem
Los investigadores descubrieron que, en términos de eficiencia, su algoritmo de grueso a fino superó a las alternativas (por ejemplo, políticas de solo grueso o de fino desde cero) de manera consistente en todas las tareas.
Pasará algún tiempo antes de que veamos robots que cambian de forma fuera del laboratorio, pero este trabajo es un paso en la dirección correcta. Los investigadores esperan que encourage a otros a desarrollar su propio robotic blando reconfigurable que, algún día, podría atravesar el cuerpo humano o incorporarse a un dispositivo portátil.
El estudio fue publicado en el sitio net de preimpresión. arXiv.
Fuente: MIT