


{kind=link}
Generación de recuperación auggada (trapo) es un enfoque para construir sistemas de IA que mix un modelo de lenguaje con una fuente de conocimiento externo. En términos simples, la IA primero busca documentos relevantes (como artículos o páginas net) relacionadas con la consulta de un usuario, y luego utiliza esos documentos para generar una respuesta más precisa. Este método ha sido celebrado por ayudar Modelos de idiomas grandes (LLM) Manténgase actual y reduzca las alucinaciones basando sus respuestas en datos reales.
Intuitivamente, uno podría pensar que cuantos más documentos recupera una IA, mejor informado será su respuesta. Sin embargo, investigaciones recientes sugieren un giro sorprendente: cuando se trata de alimentar información a una IA, a veces menos es más.
Menos documentos, mejores respuestas
A nuevo estudio por investigadores de la Universidad Hebrea de Jerusalén exploraron cómo el número de documentos dados a un sistema RAG afecta su rendimiento. De manera essential, mantuvieron la cantidad complete de texto constante, lo que significa que si se proporcionaran menos documentos, esos documentos se ampliaron ligeramente para llenar la misma longitud que muchos documentos lo harían. De esta manera, cualquier diferencia de rendimiento podría atribuirse a la cantidad de documentos en lugar de simplemente tener una entrada más corta.
Los investigadores utilizaron un conjunto de datos de preguntas (musique) de preguntas con preguntas de trivia, cada uno originalmente combinado con 20 párrafos de Wikipedia (solo algunos de los cuales realmente contienen la respuesta, con el resto de distractores). Al recortar el número de documentos de 20 hasta solo los 2–4 verdaderamente relevantes, y acolchando a aquellos con un poco de contexto adicional para mantener una longitud consistente, crearon escenarios en los que la IA tenía menos piezas de materials que considerar, pero aún así aproximadamente las mismas palabras totales para leer.
Los resultados fueron sorprendentes. En la mayoría de los casos, los modelos de IA respondieron con mayor precisión cuando se les dieron menos documentos que el conjunto completo. El rendimiento mejoró significativamente: en algunos casos en hasta un 10% en precisión (puntaje F1) cuando el sistema usó solo el puñado de documentos de soporte en lugar de una gran colección. Este impulso contradictorio se observó en varios modelos de lenguaje de código abierto diferentes, incluidas las variantes de Meta’s Llama y otros, lo que indica que el fenómeno no está ligado a un solo modelo de IA.
Un modelo (Qwen-2) fue una excepción notable que manejó múltiples documentos sin una caída en la puntuación, pero casi todos los modelos probados tuvieron un mejor rendimiento con menos documentos en common. En otras palabras, agregar más materials de referencia más allá de la clave de las piezas relevantes en realidad perjudica su rendimiento con más frecuencia de lo que ayudó.
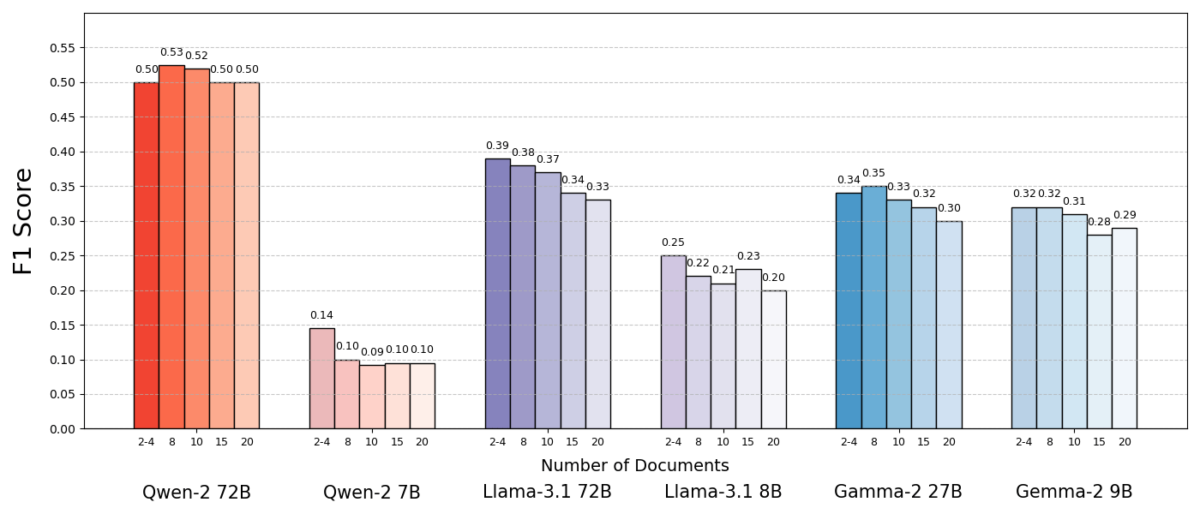
Fuente: Levy et al.
¿Por qué es esta sorpresa? Por lo common, los sistemas RAG están diseñados bajo el supuesto de que recuperar una franja de información más amplia solo puede ayudar a la IA; después de todo, si la respuesta no está en los primeros documentos, podría estar en la décima o veinte.
Este estudio voltea ese guión, lo que demuestra que se acumula indiscriminadamente en documentos adicionales puede ser contraproducente. Incluso cuando la longitud complete del texto se mantuvo constante, la mera presencia de muchos documentos diferentes (cada uno con su propio contexto y peculiaridades) hizo que la tarea de respuesta de preguntas fuera más desafiante para la IA. Parece que más allá de cierto punto, cada documento adicional introdujo más ruido que señal, confundiendo el modelo y afectando su capacidad para extraer la respuesta correcta.
Por qué menos puede estar más en trapo
Este resultado “menos es más” tiene sentido una vez que consideramos cómo los modelos de lenguaje AI procesan la información. Cuando a una IA se les da solo los documentos más relevantes, el contexto que ve está enfocado y libre de distracciones, al igual que un estudiante a quien se le ha entregado las páginas correctas para estudiar.
En el estudio, los modelos tuvieron un rendimiento significativamente mejor cuando se administró solo los documentos de apoyo, con materials irrelevante eliminado. El contexto restante no solo period más corto sino también más limpio, sino que contenía hechos que apuntaban directamente a la respuesta y nada más. Con menos documentos para hacer malabarismos, el modelo podría dedicar toda su atención a la información pertinente, lo que hace que sea menos possible que se desvíe o se confunda.
Por otro lado, cuando se recuperaron muchos documentos, la IA tuvo que examinar una mezcla de contenido relevante e irrelevante. A menudo, estos documentos adicionales eran “similares pero no relacionados”: pueden compartir un tema o palabras clave con la consulta, pero en realidad no contienen la respuesta. Tal contenido puede engañar al modelo. La IA podría desperdiciar esfuerzo tratando de conectar puntos entre documentos que en realidad no conducen a una respuesta correcta, o peor, podría fusionar información de múltiples fuentes incorrectamente. Esto aumenta el riesgo de alucinaciones, casos en que la IA genera una respuesta que suena believable pero no se basa en una sola fuente.
En esencia, alimentar demasiados documentos al modelo puede diluir la información útil e introducir detalles conflictivos, lo que dificulta que la IA decida qué es cierto.
Curiosamente, los investigadores encontraron que si los documentos adicionales eran obviamente irrelevantes (por ejemplo, texto aleatorio no relacionado), los modelos eran mejores para ignorarlos. El verdadero problema proviene de los datos de distracción que parecen relevantes: cuando todos los textos recuperados están en temas similares, la IA supone que debe usarlos todos, y puede tener dificultades para saber qué detalles son realmente importantes. Esto se alinea con la observación del estudio de que Los distractores aleatorios causaron menos confusión que los distractores realistas En la entrada. La IA puede filtrar tonterías flagrantes, pero la información sutilmente fuera del tema es una trampa resbaladiza: se cuela bajo la apariencia de relevancia y descarrila la respuesta. Al reducir el número de documentos a los verdaderamente necesarios, evitamos establecer estas trampas en primer lugar.
También hay un beneficio práctico: recuperar y procesar menos documentos scale back la sobrecarga computacional para un sistema de trapo. Cada documento que se extrae debe analizarse (integrado, leído y atendido por el modelo), que utiliza el tiempo y los recursos informáticos. Eliminar documentos superfluos hace que el sistema sea más eficiente: puede encontrar respuestas más rápido y a menor costo. En escenarios en los que mejoró la precisión al enfocarse en menos fuentes, obtenemos un beneficio mutuo: mejores respuestas y un proceso más delgado y eficiente.

Fuente: Levy et al.
Repensar trapo: instrucciones futuras
Esta nueva evidencia de que la calidad a menudo supera la cantidad en la recuperación tiene implicaciones importantes para el futuro de los sistemas de IA que dependen del conocimiento externo. Sugiere que los diseñadores de sistemas RAG deberían priorizar el filtrado inteligente y la clasificación de documentos sobre el volumen del gran volumen. En lugar de obtener 100 pasajes posibles y esperar que la respuesta esté enterrada allí en algún lugar, puede ser más sabio buscar solo los mejores altamente relevantes.
Los autores del estudio enfatizan la necesidad de métodos de recuperación para “lograr un equilibrio entre relevancia y diversidad” en la información que proporcionan a un modelo. En otras palabras, queremos proporcionar suficiente cobertura del tema para responder a la pregunta, pero no tanto que los hechos centrales se ahogan en un mar de texto extraño.
En el futuro, es possible que los investigadores exploren técnicas que ayudan a los modelos de IA a manejar múltiples documentos con más gracia. Un enfoque es desarrollar mejores sistemas de recuperación o volver a rankers que puedan identificar qué documentos realmente agregan valor y cuáles solo introducen conflictos. Otro ángulo es mejorar los modelos de lenguaje en sí mismo: si un modelo (como Qwen-2) lograra hacer frente a muchos documentos sin perder precisión, examinar cómo fue capacitado o estructurado podría ofrecer pistas para hacer que otros modelos sean más robustos. Quizás los futuros modelos de lenguaje grande incorporen mecanismos para reconocer cuándo dos fuentes dicen lo mismo (o contradicen entre sí) y se centran en consecuencia. El objetivo sería permitir que los modelos utilicen una rica variedad de fuentes sin caer presa de confusión, obteniendo lo mejor de ambos mundos (amplitud de información y claridad de enfoque).
También vale la pena señalar que como Los sistemas de IA obtienen ventanas de contexto más amplio (La capacidad de leer más texto a la vez), simplemente descargar más datos en el mensaje no es una bala de plata. El contexto más grande no significa automáticamente una mejor comprensión. Este estudio muestra que incluso si una IA puede leer técnicamente 50 páginas a la vez, darle 50 páginas de información de calidad mixta puede no dar un buen resultado. El modelo aún se beneficia de haber curado el contenido relevante para trabajar, en lugar de un vertedero indiscriminado. De hecho, la recuperación inteligente puede volverse aún más essential en la period de las ventanas de contexto gigante, para garantizar que la capacidad adicional se use para un conocimiento valioso en lugar del ruido.
Los hallazgos de “Más documentos, la misma longitud” (El documento titulado) fomenta un reexamen de nuestras suposiciones en la investigación de IA. A veces, alimentar a una IA todos los datos que tenemos no es tan efectivo como pensamos. Al centrarnos en las piezas de información más relevantes, no solo mejoramos la precisión de las respuestas generadas por IA, sino que también hacemos que los sistemas sean más eficientes y más fáciles de confiar. Es una lección contraintuitiva, pero una con ramificaciones emocionantes: los sistemas de trapo futuros pueden ser tanto más inteligentes como más delgados al elegir cuidadosamente menos y mejores documentos para recuperar.