


{kind=link}
Meta hoy introducido V-Jepa 2un modelo mundial de 1.2 mil millones de parámetros entrenado principalmente en video para apoyar la comprensión, la predicción y la planificación en sistemas robóticos. Construido en la arquitectura predictiva de incrustación conjunta (JEPA), el modelo está diseñado para ayudar a los robots y otros “agentes de IA” a navegar entornos y tareas desconocidas con una capacitación limitada específica de dominio.
V-JEPA 2 sigue un proceso de capacitación en dos etapas, todo sin anotación humana adicional. En la primera etapa auto-supervisada, el modelo aprende de más de 1 millón de horas de video y 1 millón de imágenes, capturando patrones de interacción física. La segunda etapa introduce el aprendizaje condicionado por la acción utilizando un pequeño conjunto de datos de management de robots (aproximadamente 62 horas), lo que permite que el modelo tenga en cuenta las acciones de los agentes al predecir los resultados. Esto hace que el modelo sea utilizable para la planificación y las tareas de management de circuito cerrado.
Meta dijo que ya ha probado este nuevo modelo en robots en sus laboratorios. Meta informa que V-JEPA 2 funciona bien en tareas robóticas comunes como y elige y el lugar, utilizando representaciones de objetivos basadas en la visión. Para tareas más simples como Choose and Place, el sistema genera acciones candidatas y las evalúa en función de los resultados predichos. Para tareas más difíciles, como recoger un objeto y colocarlo en el lugar correcto, V-JEPA2 usa una secuencia de subconsportes visuales para guiar el comportamiento.
En las pruebas internas, Meta dijo que el modelo mostró una capacidad prometedora para generalizar a nuevos objetos y entornos, con tasas de éxito que van del 65% al 80% en las tareas de pick-y lugar en entornos previamente invisibles.
“Creemos que los modelos mundiales marcarán una nueva period para la robótica, permitiendo a los agentes de IA del mundo actual ayudar con tareas y tareas físicas sin necesidad de cantidades astronómicas de datos de entrenamiento robótico”, dijo el científico de IA de Meta, Yann Lecun.
Aunque V-JepA 2 muestra mejoras sobre modelos anteriores, Meta AI dijo que sigue habiendo una brecha notable entre el modelo y el rendimiento humano en estos puntos de referencia. Meta sugiere que esto apunta a la necesidad de modelos que puedan operar a través de múltiples escalas de tiempo y modalidades, como la incorporación de información de audio o táctil.
Para evaluar el progreso en la comprensión física del video, Meta también está lanzando los siguientes tres puntos de referencia:
- Intphys 2: Evalúa la capacidad del modelo para distinguir entre escenarios físicamente plausibles e inverosímil.
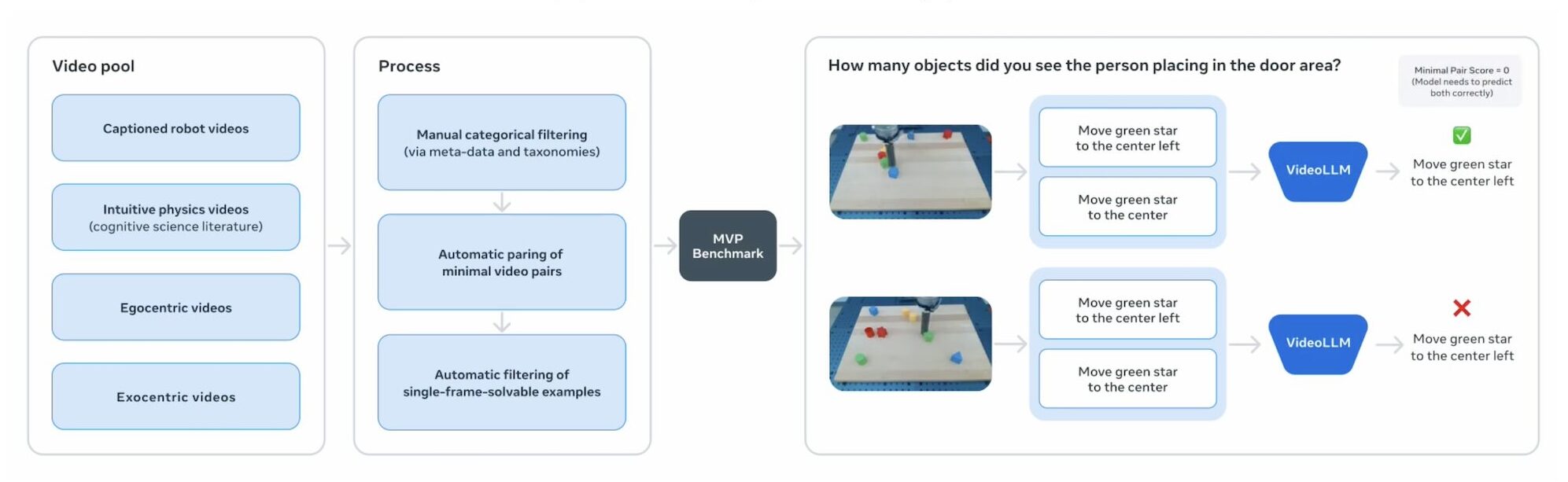
- MVPBENCH: Prueba si los modelos dependen de la comprensión genuina en lugar de los atajos de conjunto de datos en la respuesta de las preguntas de video.
- Causalvqa: Examina el razonamiento sobre causa y efecto, anticipación y contrafactuales.
Los puntos de management del código V-JEPA 2 están disponibles para uso comercial y de investigación, con meta objetivo de fomentar la exploración más amplia de los modelos mundiales en robótica y IA incorporada.
Meta se une a otros líderes tecnológicos en el desarrollo de sus propios modelos mundiales. Google DeepMind ha estado desarrollando su propia versión, Genie, que puede simular entornos 3D completos. Y World Labs, una startup fundada por Fei-Fei Li, recaudó $ 230 millones para construir grandes modelos mundiales.