


{kind=link}
Como investigadores de visión por computadora, creemos que cada píxel puede contar una historia. Sin embargo, parece haber un bloqueo en el escritor cuando se trata de imágenes de gran tamaño. Las imágenes grandes ya no son raras: las cámaras que llevamos en nuestros bolsillos y las que orbitan alrededor de nuestro planeta toman fotografías tan grandes y detalladas que estiran nuestros mejores modelos y {hardware} actuales hasta el punto de ruptura al manipularlos. Generalmente, nos enfrentamos a un aumento cuadrático en el uso de memoria en función del tamaño de la imagen.
Hoy en día, tomamos una de dos opciones subóptimas cuando manejamos imágenes grandes: reducir la resolución o recortar. Estos dos métodos provocan pérdidas significativas en la cantidad de información y contexto presentes en una imagen. Echamos otro vistazo a estos enfoques e introducimos $x$T, un nuevo marco para modelar imágenes grandes de un extremo a otro en GPU contemporáneas y, al mismo tiempo, agrega de manera efectiva el contexto international con detalles locales.

Arquitectura para el framework $x$T.
¿Por qué molestarse con imágenes grandes de todos modos?
¿Por qué molestarse en manejar imágenes grandes de todos modos? Imagínese frente a su televisor, viendo su equipo de fútbol favorito. El campo está lleno de jugadores y la acción ocurre solo en una pequeña porción de la pantalla a la vez. Sin embargo, ¿estaría satisfecho si sólo pudiera ver una pequeña región alrededor de donde se encontraba actualmente la pelota? Alternativamente, ¿te sentirías satisfecho viendo el juego en baja resolución? Cada píxel cuenta una historia, sin importar lo lejos que estén. Esto es cierto en todos los ámbitos, desde la pantalla de su televisor hasta un patólogo que ve una diapositiva de gigapíxeles para diagnosticar pequeñas zonas de cáncer. Estas imágenes son tesoros de información. Si no podemos explorar completamente la riqueza porque nuestras herramientas no pueden manejar el mapa, ¿qué sentido tiene?

Los deportes son divertidos cuando sabes lo que está pasando.
Ahí es precisamente donde reside hoy la frustración. Cuanto más grande es la imagen, más necesitamos alejarnos para ver la imagen completa y acercarnos para ver los detalles esenciales, lo que hace que sea un desafío captar tanto el bosque como los árboles simultáneamente. La mayoría de los métodos actuales obligan a elegir entre perder de vista el bosque o perderse los árboles, y ninguna de las dos opciones es buena.
Cómo $x$T intenta solucionar esto
Imagínese intentar resolver un enorme rompecabezas. En lugar de abordar todo de una vez, lo cual sería abrumador, se comienza con secciones más pequeñas, se observa detenidamente cada pieza y luego se descubre cómo encajan en el panorama common. Eso es básicamente lo que hacemos con imágenes grandes con $x$T.
$x$T toma estas imágenes gigantes y las corta jerárquicamente en pedazos más pequeños y digeribles. Pero no se trata sólo de hacer las cosas más pequeñas. Se trata de comprender cada pieza por sí misma y luego, utilizando algunas técnicas inteligentes, descubrir cómo se conectan estas piezas a mayor escala. Es como tener una conversación con cada parte de la imagen, conocer su historia y luego compartirla con las otras partes para obtener la narrativa completa.
Tokenización anidada
En el núcleo de $x$T se encuentra el concepto de tokenización anidada. En términos simples, la tokenización en el ámbito de la visión por computadora es related a cortar una imagen en pedazos (tokens) que un modelo puede digerir y analizar. Sin embargo, $x$T lleva esto un paso más allá al introducir una jerarquía en el proceso; por lo tanto, anidado.
Think about que tiene la tarea de analizar un mapa detallado de la ciudad. En lugar de intentar abarcar todo el mapa de una vez, lo divides en distritos, luego en vecindarios dentro de esos distritos y, finalmente, en calles dentro de esos vecindarios. Este desglose jerárquico facilita la gestión y la comprensión de los detalles del mapa y, al mismo tiempo, realiza un seguimiento de dónde encaja todo en el panorama common. Esa es la esencia de la tokenización anidada: dividimos una imagen en regiones, cada una de las cuales se puede dividir en subregiones adicionales dependiendo del tamaño de entrada esperado por una columna vertebral de visión (lo que llamamos codificador de región), antes de ser parcheado para ser procesado por el codificador de esa región. Este enfoque anidado nos permite extraer características a diferentes escalas a nivel native.
Coordinación de codificadores de contexto y región
Una vez que una imagen está claramente dividida en tokens, $x$T emplea dos tipos de codificadores para darle sentido a estas piezas: el codificador de región y el codificador de contexto. Cada uno desempeña un papel distinto a la hora de reconstruir la historia completa de la imagen.
El codificador de regiones es un “experto native” independiente que convierte regiones independientes en representaciones detalladas. Sin embargo, dado que cada región se procesa de forma aislada, no se comparte información en toda la imagen. El codificador de región puede ser cualquier columna vertebral de visión de última generación. En nuestros experimentos hemos utilizado transformadores de visión jerárquica como nadar y hiera y también CNN como ConvNext!
Ingrese al codificador de contexto, el gurú del panorama common. Su trabajo es tomar las representaciones detalladas de los codificadores de región y unirlas, asegurando que los conocimientos de un token se consideren en el contexto de los demás. El codificador de contexto es generalmente un modelo de secuencia larga. experimentamos con Transformador-XL (y nuestra variante llamada Hiper) y Tipo de serpiente venenosaaunque podrías usar antiguo y otros nuevos avances en esta área. Aunque estos modelos de secuencia larga generalmente están diseñados para el lenguaje, demostramos que es posible utilizarlos de manera efectiva para tareas de visión.
La magia de $x$T está en cómo se combinan estos componentes (la tokenización anidada, los codificadores de región y los codificadores de contexto). Al dividir primero la imagen en partes manejables y luego analizar sistemáticamente estas partes, tanto de forma aislada como en conjunto, $x$T logra mantener la fidelidad de los detalles de la imagen authentic y al mismo tiempo integra el contexto de larga distancia con el contexto common. mientras adapta imágenes masivas, de extremo a extremo, en GPU contemporáneas.
Resultados
Evaluamos $x$T en tareas de referencia desafiantes que abarcan líneas de base de visión por computadora bien establecidas hasta tareas rigurosas de imágenes de gran tamaño. En specific, experimentamos con iNaturalista 2018 para la clasificación de especies de grano fino, xView3-SAR para la segmentación dependiente del contexto, y MS-COCO para la detección.
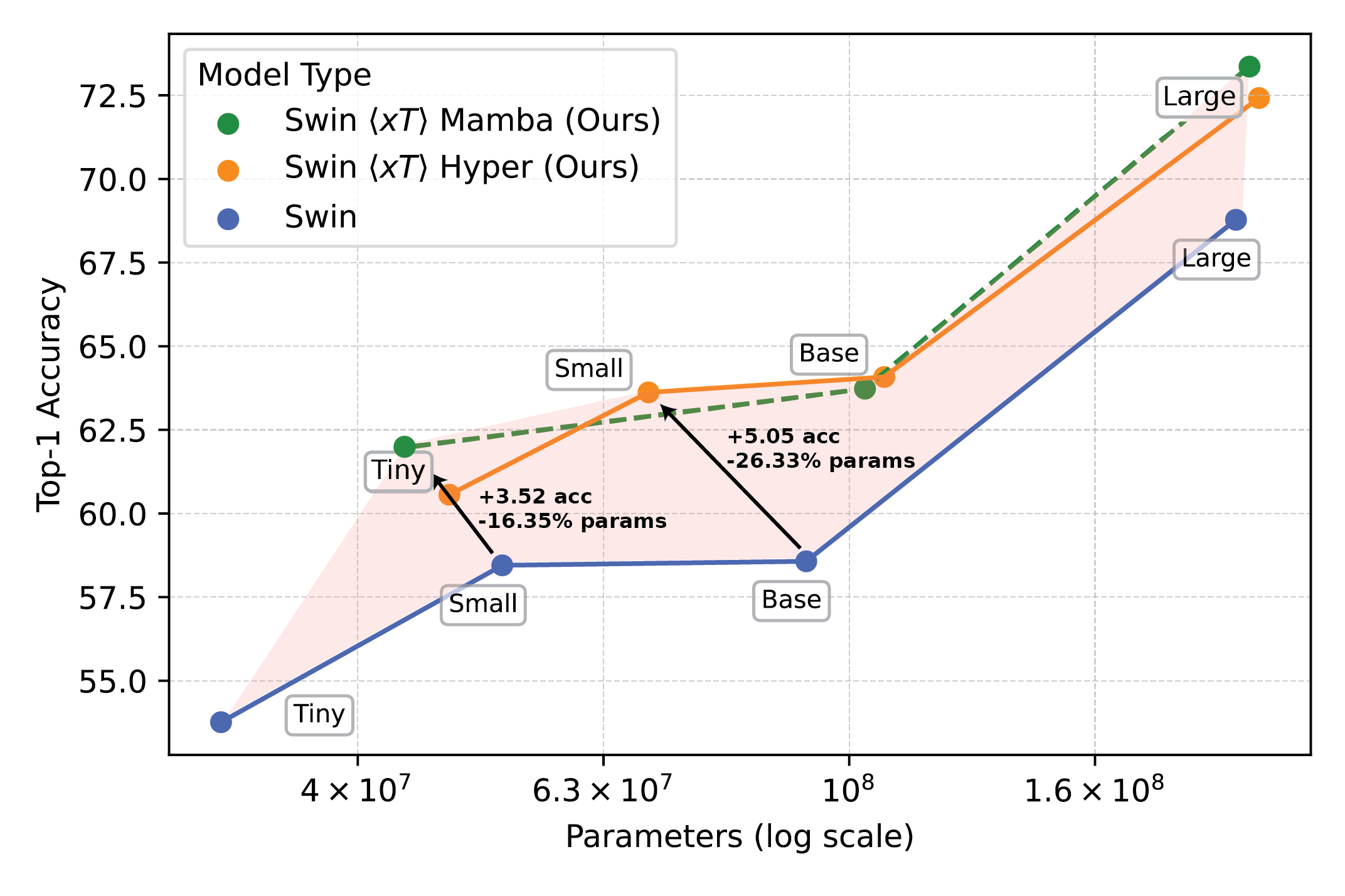
Los potentes modelos de visión utilizados con $x$T establecen una nueva frontera en tareas posteriores, como la clasificación detallada de especies.
Nuestros experimentos muestran que $x$T puede lograr una mayor precisión en todas las tareas posteriores con menos parámetros y al mismo tiempo utilizar mucha menos memoria por región que las líneas de base de última generación.*. Podemos modelar imágenes de hasta 29.000 x 25.000 píxeles en A100 de 40 GB, mientras que las líneas base comparables se quedan sin memoria con solo 2.800 x 2.800 píxeles.
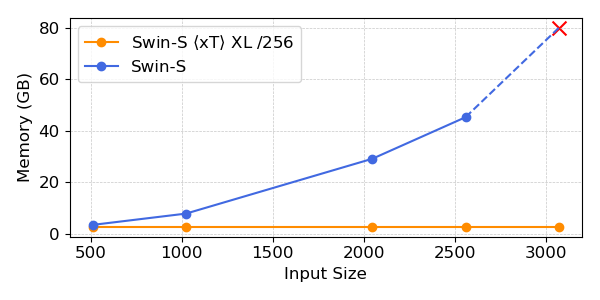
Los potentes modelos de visión utilizados con $x$T establecen una nueva frontera en tareas posteriores, como la clasificación detallada de especies.
*Dependiendo de su elección de modelo de contexto, como Transformer-XL.
Por qué esto importa más de lo que piensas
Este enfoque no sólo es genial; es necesario. Para los científicos que siguen el cambio climático o los médicos que diagnostican enfermedades, es un punto de inflexión. Significa crear modelos que comprendan la historia completa, no sólo fragmentos. En el monitoreo ambiental, por ejemplo, ser capaz de ver tanto los cambios más amplios en vastos paisajes como los detalles de áreas específicas puede ayudar a comprender el panorama más amplio del impacto climático. En el ámbito de la atención sanitaria, podría significar la diferencia entre detectar una enfermedad a tiempo o no.
No pretendemos haber resuelto todos los problemas del mundo de una sola vez. Esperamos que con $x$T hayamos abierto la puerta a lo que es posible. Estamos entrando en una nueva period en la que no tenemos que ceder en la claridad o amplitud de nuestra visión. $x$T es nuestro gran salto hacia modelos que pueden hacer malabarismos con las complejidades de imágenes a gran escala sin sudar.
Hay mucho más terreno por recorrer. La investigación evolucionará y, con suerte, también nuestra capacidad para procesar imágenes aún más grandes y complejas. De hecho, estamos trabajando en secuelas de $x$T que ampliarán aún más esta frontera.
En conclusión
Para un tratamiento completo de este trabajo, consulte el artículo en arXiv. El pagina del proyecto contiene un enlace a nuestro código publicado y pesos. Si encuentra útil el trabajo, cítelo a continuación:
@article{xTLargeImageModeling,
title={xT: Nested Tokenization for Bigger Context in Massive Pictures},
creator={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya},
journal={arXiv preprint arXiv:2403.01915},
12 months={2024}
}