


{kind=link}
Preprocesamiento de datos Elimina los errores, llena la información faltante y estandariza los datos para ayudar a los algoritmos a encontrar patrones reales en lugar de confundirse por ruido o inconsistencias.
Cualquier algoritmo necesita que se limpien los datos correctamente organizados en formatos estructurados antes de aprender de los datos. El proceso de aprendizaje automático requiere el preprocesamiento de datos como su paso elementary para garantizar que los modelos mantengan su precisión y efectividad operativa al tiempo que garantiza la confiabilidad.
La calidad del trabajo de preprocesamiento transforma las colecciones de datos básicos en concepts importantes junto con resultados confiables para todas las iniciativas de aprendizaje automático. Este artículo lo guía a través de los pasos clave del preprocesamiento de datos para el aprendizaje automático, desde la limpieza y la transformación de datos hasta herramientas, desafíos y consejos del mundo actual para aumentar el rendimiento del modelo.
Comprender los datos sin procesar
Los datos sin procesar son el punto de partida para cualquier Proyecto de aprendizaje automáticoy el conocimiento de su naturaleza es elementary.
El proceso de tratar con datos sin procesar puede ser desigual a veces. A menudo viene con ruido, entradas irrelevantes o engañosas que pueden sesgar los resultados.
Los valores faltantes son otro problema, especialmente cuando los sensores fallan o se omiten las entradas. Los formatos inconsistentes también aparecen a menudo: los campos de fecha pueden usar diferentes estilos, o los datos categóricos pueden ingresarse de varias maneras (por ejemplo, “sí”, “y”, “1”).
Reconocer y abordar estos problemas es esencial antes de alimentar los datos en cualquier algoritmo de aprendizaje automático. La entrada limpia conduce a una salida más inteligente.
Preprocesamiento de datos en minería de datos versus aprendizaje automático

Si bien tanto la minería de datos como el aprendizaje automático dependen del preprocesamiento para preparar datos para el análisis, sus objetivos y procesos difieren.
En la minería de datos, el preprocesamiento se centra en hacer que los conjuntos de datos grandes y no estructurados sean utilizables para el descubrimiento y resumen de patrones. Esto incluye la limpieza, la integración y la transformación, y el formato de datos para consultas, agrupaciones o minería de reglas de asociación, tareas que no siempre requieren capacitación en modelos.
A diferencia del aprendizaje automático, donde el preprocesamiento a menudo se centra en mejorar la precisión del modelo y reducir el sobreajuste, la minería de datos tiene como objetivo la interpretabilidad y las concepts descriptivas. La ingeniería de características se trata menos de predicción y más de encontrar tendencias significativas.
Además, los flujos de trabajo de minería de datos pueden incluir discretización y binning con más frecuencia, particularmente para clasificar variables continuas. Si bien el preprocesamiento de ML puede detenerse una vez que se prepara el conjunto de datos de entrenamiento, la minería de datos puede volver a la exploración iterativa.
Por lo tanto, los objetivos de preprocesamiento: extracción de información versus rendimiento predictivo, establecen el tono de cómo se forman los datos en cada campo. A diferencia del aprendizaje automático, donde el preprocesamiento a menudo se centra en mejorar la precisión del modelo y reducir el sobreajuste, la minería de datos tiene como objetivo la interpretabilidad y las concepts descriptivas.
La ingeniería de características se trata menos de predicción y más de encontrar tendencias significativas.
Además, los flujos de trabajo de minería de datos pueden incluir discretización y binning con más frecuencia, particularmente para clasificar variables continuas. Si bien el preprocesamiento de ML puede detenerse una vez que se prepara el conjunto de datos de entrenamiento, la minería de datos puede volver a la exploración iterativa.
Pasos centrales en el preprocesamiento de datos
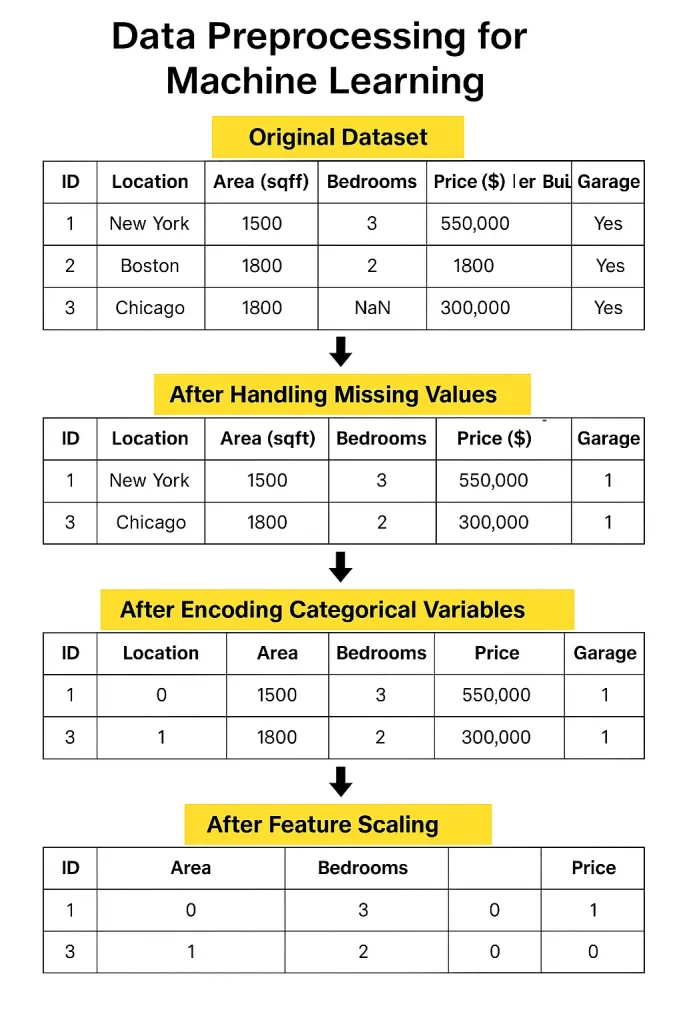
1. Limpieza de datos
Los datos del mundo actual a menudo vienen con valores faltantes, espacios en blanco en su hoja de cálculo que deben llenarse o eliminarse cuidadosamente.
Luego están los duplicados, que pueden ponderar injustamente sus resultados. Y no olvide los valores atípicos: valores extremos que pueden atraer su modelo en la dirección incorrecta si no se controla.
Estos pueden desechar su modelo, por lo que es posible que deba limitarlos, transformarlos o excluirlos.
2. Transformación de datos
Una vez que se limpian los datos, debe formatearlos. Si sus números varían salvajemente en el rango, Normalización o estandarización ayuda a escalarlos de manera consistente.
Datos categóricos, al igual que los nombres de los países o los tipos de productos, deben convertirse en números a través de la codificación.
Y para algunos conjuntos de datos, ayuda a agrupar valores similares en los contenedores para reducir el ruido y resaltar los patrones.
3. Integración de datos
A menudo, sus datos vendrán de diferentes lugares, archivos, bases de datos o herramientas en línea. Fusionar todo puede ser complicado, especialmente si la misma información se ve diferente en cada fuente.
Los conflictos de esquema, donde la misma columna tiene diferentes nombres o formatos, son comunes y necesitan una resolución cuidadosa.
4. Reducción de datos
Massive Knowledge puede abrumar a los modelos y aumentar el tiempo de procesamiento. Al seleccionar solo las características más útiles o reducir las dimensiones utilizando técnicas como PCA o muestreo, su modelo es más rápido y, a menudo, más preciso.
Herramientas y bibliotecas para el preprocesamiento
- Lear es excelente para la mayoría de las tareas de preprocesamiento básicas. Tiene funciones incorporadas para llenar los valores faltantes, las características de escala, las categorías de codificación y seleccionar características esenciales. Es una biblioteca sólida y amigable para principiantes con todo lo que necesita para comenzar.
- Pandas es otra biblioteca esencial. Es increíblemente útil para explorar y manipular datos.
- Validación de datos TensorFlow Puede ser útil si está trabajando con proyectos a gran escala. Verifica los problemas de datos y garantiza que su entrada siga la estructura correcta, algo que es fácil de pasar por alto.
- DVC (Management de versiones de datos) es excelente cuando su proyecto crece. Realiza un seguimiento de las diferentes versiones de sus datos y pasos de preprocesamiento para que no pierda su trabajo o deseteje las cosas durante la colaboración.
Desafíos comunes
Uno de los mayores desafíos hoy en día es administrar datos a gran escala. Cuando tiene millones de filas de diferentes fuentes diariamente, organizarlas y limpiarlas se convierte en una tarea seria.
Abordar estos desafíos requiere buenas herramientas, planificación sólida y monitoreo constante.
Otro problema importante es automatizar el preprocesamiento tuberías. En teoría, suena genial; Simplemente configure un flujo para limpiar y preparar sus datos automáticamente.
Pero en realidad, los conjuntos de datos varían, y las reglas que funcionan para uno podrían descomponerse para otro. Todavía necesita un ojo humano para verificar los casos de borde y hacer llamadas de juicio. La automatización ayuda, pero no siempre es plug-and-play.
Incluso si comienza con datos limpios, las cosas cambian, los formatos de cambio, la actualización de las fuentes y los errores se colan. Sin verificaciones regulares, sus datos perfectos una vez se desmoronan lentamente, lo que lleva a concepts poco confiables y un rendimiento del modelo deficiente.
Mejores prácticas
Aquí hay algunas mejores prácticas que pueden marcar una gran diferencia en el éxito de su modelo. Vamos a desglosarlos y examinar cómo se desarrollan en situaciones del mundo actual.
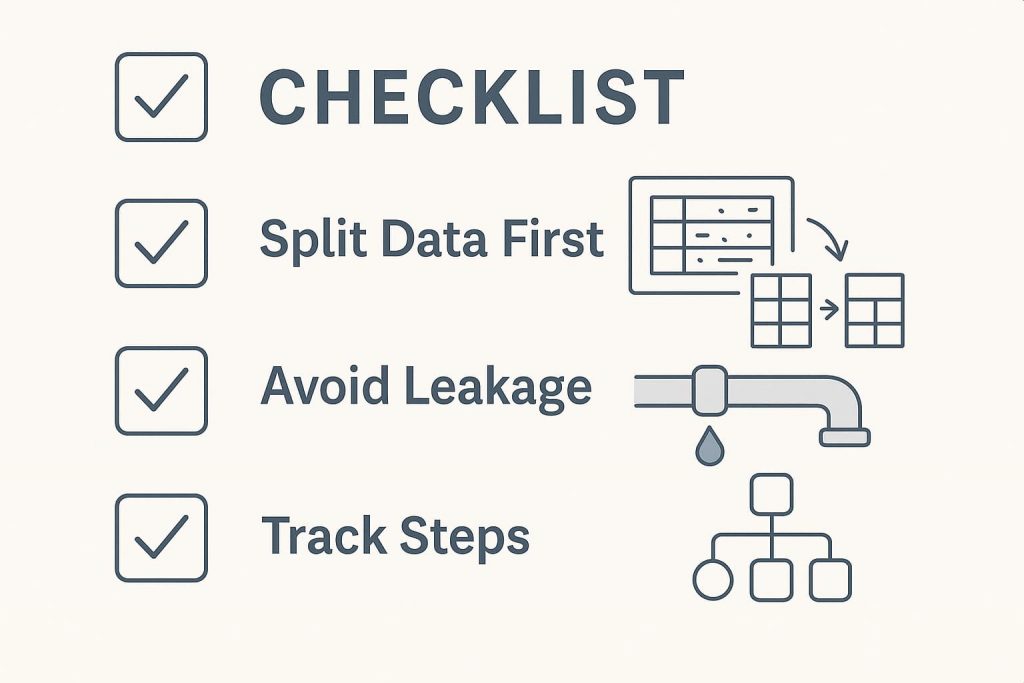
1. Comience con una división de datos adecuada
Un error que cometen muchos principiantes es hacer todo el preprocesamiento en el conjunto de datos completo antes de dividirlo en conjuntos de entrenamiento y prueba. Pero este enfoque puede introducir accidentalmente sesgo.
Por ejemplo, si escala o normaliza todo el conjunto de datos antes de la división, la información del conjunto de pruebas puede sangrar en el proceso de entrenamiento, lo que se denomina fuga de datos.
Siempre divida sus datos primero, luego aplique el preprocesamiento solo en el conjunto de capacitación. Más tarde, transforme el conjunto de pruebas utilizando los mismos parámetros (como la media y la desviación estándar). Esto mantiene las cosas justas y asegura que su evaluación sea honesta.
2. Evitar la fuga de datos
La fuga de datos es astuta y una de las formas más rápidas de arruinar un modelo de aprendizaje automático. Ocurre cuando el modelo aprende algo a lo que no tendría acceso en una situación del mundo actual, trato.
Las causas comunes incluyen el uso de etiquetas objetivo en ingeniería de características o dejar que los datos futuros influyan en las predicciones actuales. La clave es pensar siempre en la información que su modelo tendría de manera realista en el momento de la predicción y mantenerla limitada a eso.
3. Rastree cada paso
A medida que avanza a través de su tubería de preprocesamiento, manejar valores faltantes, codificar variables, características de escala y realizar un seguimiento de sus acciones son esenciales no solo para su propia memoria sino también para la reproducibilidad.
Documentar cada paso asegura que otros (o el futuro usted) puedan volver sobre su camino. Herramientas como DVC (management de versión de datos) o un easy Cuaderno de jupyter Con anotaciones claras puede facilitar esto. Este tipo de seguimiento también ayuda cuando su modelo se desempeña inesperadamente: puede regresar y descubrir qué salió mal.
Ejemplos del mundo actual
Para ver cuánta diferencia hace el preprocesamiento, considere un Estudio de caso que involucra la predicción de la rotación de clientes en una empresa de telecomunicaciones. Inicialmente, su conjunto de datos sin procesar incluía valores faltantes, formatos inconsistentes y características redundantes. El primer modelo entrenado en estos datos desordenados apenas alcanzó la precisión del 65%.
Después de aplicar el preprocesamiento adecuado, imputar valores faltantes, codificar variables categóricas, normalizar las características numéricas y eliminar columnas irrelevantes, la precisión se disparó hasta más del 80%. La transformación no estaba en el algoritmo sino en la calidad de los datos.
Otro gran ejemplo proviene de la atención médica. Un equipo trabajando en Predecir la enfermedad cardíaca
Utilizó un conjunto de datos público que incluía tipos de datos mixtos y campos faltantes.
Aplicaron binning a grupos de edad, manejaron valores atípicos utilizando RobustScaler, y un solo candado codificó varias variables categóricas. Después del preprocesamiento, la precisión del modelo mejoró del 72% al 87%, lo que demuestra que la forma en que prepara sus datos a menudo importa más que qué algoritmo elija.
En resumen, el preprocesamiento es la base de cualquier proyecto de aprendizaje automático. Siga las mejores prácticas, mantenga las cosas transparentes y no subestimes su impacto. Cuando se hace bien, puede llevar su modelo de promedio a excepcional.
Preguntas frecuentes (preguntas frecuentes)
1. ¿Es el preprocesamiento diferente para el aprendizaje profundo?
Sí, pero solo un poco. Aprendizaje profundo Todavía necesita datos limpios, solo menos características manuales.
2. ¿Cuánto preprocesamiento es demasiado?
Si elimina patrones significativos o duele la precisión del modelo, es possible que lo haya exagerado.
3. ¿Se puede omitir el preprocesamiento con suficientes datos?
No. Más datos ayudan, pero la entrada de mala calidad aún conduce a malos resultados.
3. ¿Todos los modelos necesitan el mismo preprocesamiento?
No. Cada algoritmo tiene diferentes sensibilidades. Lo que funciona para uno no puede adaptarse a otro.
4. ¿Es siempre necesaria la normalización?
Sobre todo, sí. Especialmente para algoritmos a distancia como KNN o SVMS.
5. ¿Puedes automatizar el preprocesamiento por completo?
No del todo. Las herramientas ayudan, pero el juicio humano todavía se necesita para el contexto y la validación.
¿Por qué rastrear los pasos de preprocesamiento?
Asegura la reproducibilidad y ayuda a identificar lo que está mejorando o perjudicando el rendimiento.
Conclusión
El preprocesamiento de datos no es solo un paso preliminar, y es la base del buen aprendizaje automático. Los datos limpios y consistentes conducen a modelos que no solo son precisos sino también confiables. Desde eliminar los duplicados hasta elegir la codificación adecuada, cada paso es importante. Saltar o mal manejo del preprocesamiento a menudo conduce a resultados ruidosos o concepts engañosas.
Y a medida que evolucionan los desafíos de datos, una sólida comprensión de la teoría y las herramientas se vuelve aún más valiosa. Muchas rutas de aprendizaje prácticas hoy, como las que se encuentran en la ciencia de datos integral
Si está buscando construir habilidades fuertes y de ciencia de datos del mundo actual, incluida la experiencia práctica con técnicas de preprocesamiento, considere explorar el Grasp Knowledge Science & Machine Studying en Python Programa de gran aprendizaje. Está diseñado para cerrar la brecha entre la teoría y la práctica, ayudándole a aplicar estos conceptos con confianza en proyectos reales.