


{kind=link}
En este artículo, nos centraremos en las unidades recurrentes cerradas (grus), una alternativa más directa pero poderosa que ha ganado tracción por su eficiencia y rendimiento.
Ya sea que sea nuevo en el modelado de secuencias o que busque agudizar su comprensión, esta guía explicará cómo funcionan los grus, dónde brillan y por qué importan en el panorama de aprendizaje profundo de hoy.
En aprendizaje profundono todos los datos llegan a fragmentos ordenados e independientes. Gran parte de lo que encontramos: lenguaje, música, precios de acciones, se desarrolla con el tiempo, con cada momento moldeado por lo que vino antes. Ahí es donde entran los datos secuenciales, y con ellos, la necesidad de modelos que entiendan el contexto y la memoria.
Redes neuronales recurrentes (RNN) se construyeron para abordar el desafío de trabajar con secuencias, lo que hace posible que las máquinas sigan patrones con el tiempo, como cómo las personas procesan el lenguaje o los eventos.
Aún así, los RNN tradicionales tienden a perder el rastro de información más antigua, lo que puede conducir a predicciones más débiles. Es por eso que los modelos más nuevos como LSTMS y Grus entraron en la imagen, diseñados para aferrarse mejor a los detalles relevantes en secuencias más largas.
¿Qué son los grus?
Las unidades recurrentes cerradas, o Grus, son un tipo de purple neuronal Eso ayuda a las computadoras a dar sentido a las secuencias: cosas como oraciones, sequence de tiempo o incluso música. A diferencia de las redes estándar que tratan cada entrada por separado, los grus recuerdan lo que vino antes, lo cual es clave cuando el contexto importa.

El trabajo de los grus utilizando dos “puertas” principales para administrar la información. La puerta de actualización determine cuánto del pasado debe mantenerse alrededor, y la puerta de reinicio ayuda al modelo a descubrir cuánto del pasado olvidar cuando ve una nueva entrada.
Estas puertas permiten que el modelo se concentre en lo que es importante e ignora los datos irrelevantes o el ruido.
A medida que entran los nuevos datos, estas puertas trabajan juntas para combinar lo antiguo y lo nuevo de manera inteligente. Si algo de antes en la secuencia todavía importa, el Gru lo mantiene. Si no es así, el Gru lo deja ir.
Este equilibrio ayuda a aprender patrones a través del tiempo sin sentirse abrumado.
En comparación con los LSTM (memoria a largo plazo), que usan tres puertas y una estructura de memoria más compleja, los grus son más ligeros y más rápidos. No necesitan tantos parámetros y generalmente son más rápidos de entrenar.
Los grus funcionan igual de bien en muchos casos, especialmente cuando el conjunto de datos no es masivo o demasiado complejo. Eso los convierte en una elección sólida para muchas tareas de aprendizaje profundo que involucran secuencias.
En normal, Grus ofrece una mezcla práctica de potencia y simplicidad. Están diseñados para capturar patrones esenciales en datos secuenciales sin complicar sobre las cosas, lo cual es una cualidad que los hace efectivos y eficientes en el uso del mundo actual.
Ecuaciones y funcionamiento de GRU
Una celda GRU utiliza algunas ecuaciones clave para decidir qué información mantener y qué descartar a medida que se mueve a través de una secuencia. Gru combina información antigua y nueva basada en lo que deciden las puertas. Esto le permite retener el contexto práctico sobre secuencias largas, ayudando al modelo a comprender las dependencias que se extienden a lo largo del tiempo.
Diagrama de Gru
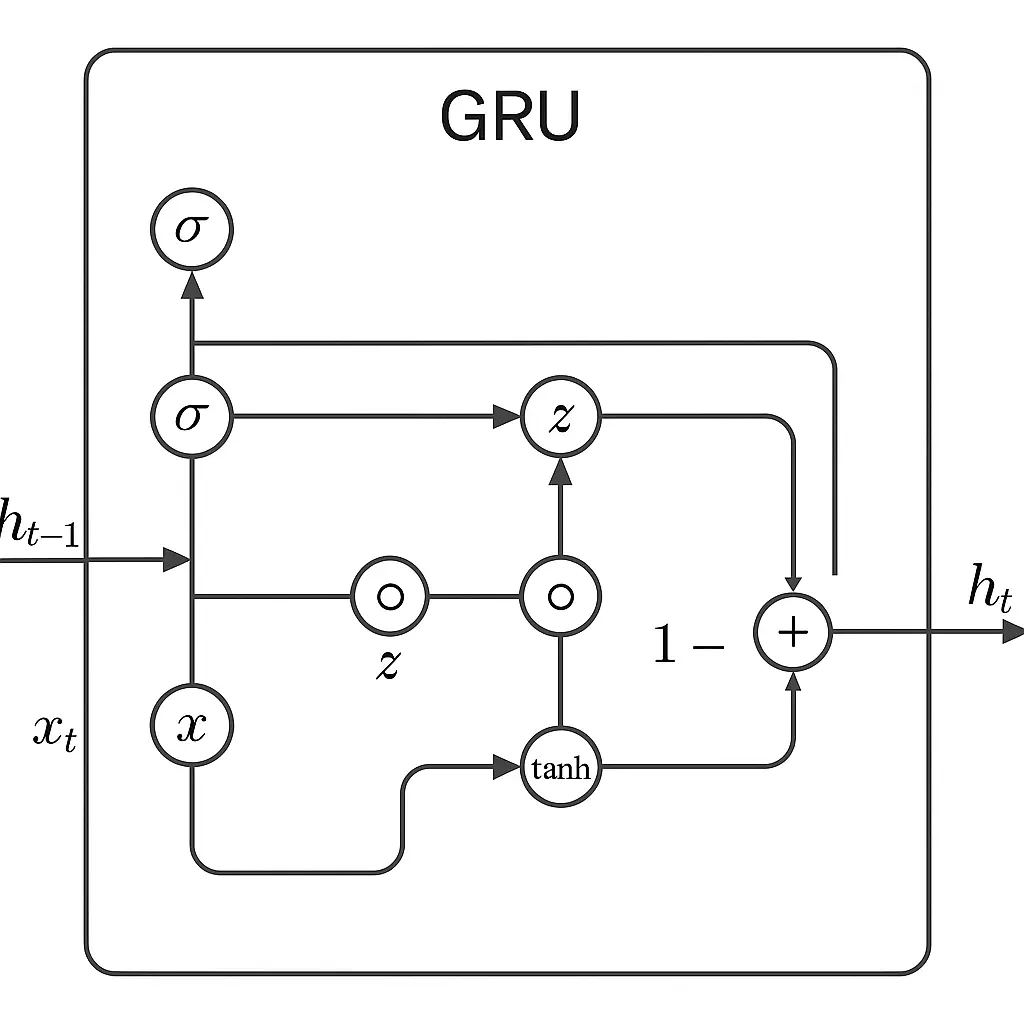
Ventajas y limitaciones de Grus
Ventajas
- Los grus tienen la reputación de ser easy y efectivo.
- Una de sus mayores fortalezas es cómo manejan la memoria. Están diseñados para aferrarse a las cosas importantes de anteriormente en una secuencia, lo que ayuda a trabajar con datos que se desarrollan con el tiempo, como el lenguaje, el audio o las sequence de tiempo.
- Los grus usan menos parámetros que algunos de sus contrapartes, especialmente LSTM. Con menos piezas móviles, entrenan más rápido y necesitan menos datos para ponerse en marcha. Esto es excelente cuando se les abrevia de la alimentación de la computación o se trabaja con conjuntos de datos más pequeños.
- También tienden a converger más rápido. Eso significa que el proceso de capacitación generalmente lleva menos tiempo alcanzar un buen nivel de precisión. Si está en un entorno donde importa la iteración rápida, este puede ser un beneficio actual.
Limitaciones
- En las tareas donde la secuencia de entrada es muy larga o compleja, es posible que no funcionen tan bien como LSTM. Los LSTM tienen una unidad de memoria adicional que les ayuda a lidiar con esas dependencias más profundas de manera más efectiva.
- Grus también lucha con secuencias muy largas. Si bien son mejores que los RNN simples, aún pueden perder el seguimiento de la información anteriormente en la entrada. Eso puede ser un problema si sus datos tienen dependencias extendidas muy separadas, como el comienzo y el remaining de un párrafo largo.
Entonces, mientras Grus alcanzó un buen equilibrio para muchos trabajos, no son una solución common. Brillan en configuraciones livianas y eficientes, pero pueden quedarse cortas cuando la tarea exige más memoria o matices.
Aplicaciones de grus en escenarios del mundo actual
Las unidades recurrentes cerradas (Grus) se están utilizando ampliamente en varias aplicaciones del mundo actual debido a su capacidad para procesar datos secuenciales.
- En el procesamiento del lenguaje pure (NLP), las grus ayudan con tareas como la traducción automática y el análisis de sentimientos.
- Estas capacidades son especialmente relevantes en prácticas Proyectos de PNL Al igual que los chatbots, la clasificación de texto o la generación de idiomas, donde la capacidad de comprender y responder a las secuencias juega de manera significativa un papel central.
- En el pronóstico de sequence de tiempo, los grus son especialmente útiles para predecir las tendencias. Piense en los precios de las acciones, las actualizaciones meteorológicas o cualquier datos que se muevan en una línea de tiempo
- Grus puede captar los patrones y ayudar a hacer conjeturas inteligentes sobre lo que vendrá después.
- Están diseñados para aferrarse a la cantidad justa de información pasada sin empantanarse, lo que ayuda a evitar problemas de entrenamiento comunes.
- En el reconocimiento de voz, los grus ayudan a convertir las palabras habladas en las escritas. Como manejan bien las secuencias, pueden ajustarse a diferentes estilos y acentos de habla, lo que hace que la salida sea más confiable.
- En el mundo médico, los grus se están utilizando para detectar patrones inusuales en los datos de los pacientes, como detectar latidos cardíacos irregulares o predecir los riesgos para la salud. Pueden examinar los registros basados en el tiempo y resaltar cosas que los médicos podrían no atrapar de inmediato.
Grus y LSTM están diseñados para manejar datos secuenciales superando problemas como los gradientes de desaparición, pero cada uno tiene sus fortalezas dependiendo de la situación.
Cuándo elegir Grus sobre LSTM u otros modelos
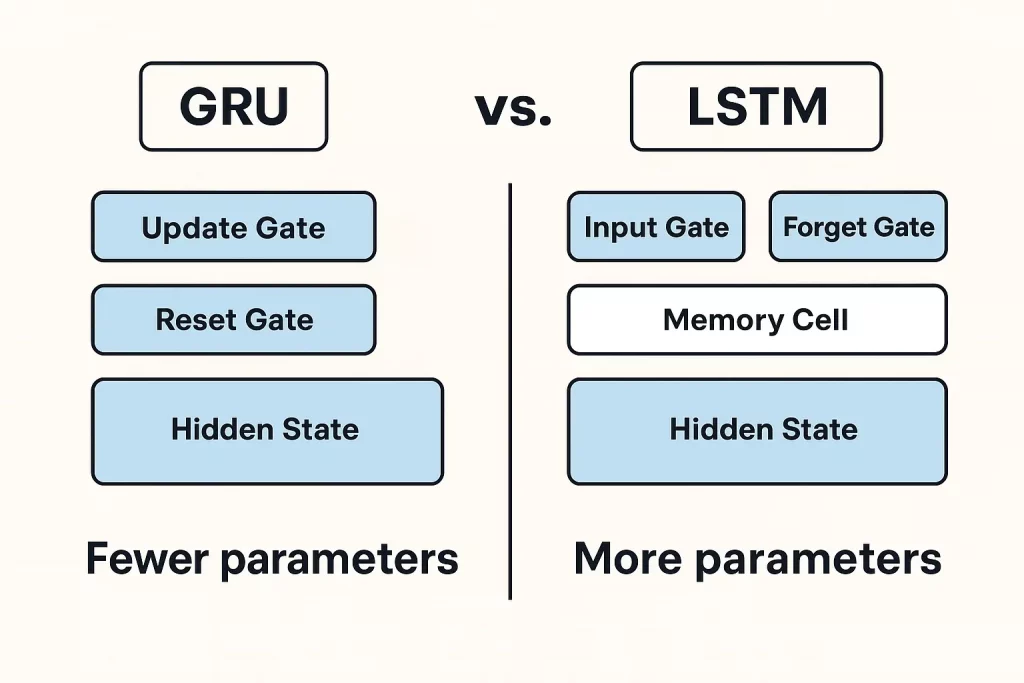
Tanto Grus como LSTM son redes neuronales recurrentes utilizadas para el procesamiento de secuencias, y se distinguen entre sí, tanto la complejidad como por las métricas computacionales.
Su simplicidad, es decir, menos parámetros, hace que Grus Prepare sea más rápido y use menos potencia computacional. Por lo tanto, se aplican ampliamente en casos de uso en los que la velocidad eclipsa que manejan recuerdos grandes y complejos, por ejemplo, análisis en línea/en vivo.
Se utilizan rutinariamente en aplicaciones que exigen un procesamiento rápido, como el reconocimiento de voz en vivo o el pronóstico sobre la marcha, donde es esencial una operación rápida y no un análisis engorroso de los datos.
Por el contrario, los LSTM admiten las aplicaciones que pueden depender en gran medida del management de memoria de grano fino, por ejemplo, traducción automática o análisis de sentimientos. Hay puertas de entrada, olvida y salida presentes en LSTM que aumentan su capacidad para procesar dependencias a largo plazo de manera eficiente.
Aunque requieren más capacidad de análisis, los LSTM generalmente se prefieren para abordar aquellas tareas que involucran secuencias extensas y dependencias complicadas, y los LSTM son expertos en dicho procesamiento de memoria.
En normal, las Grus funcionan mejor en situaciones en las que las dependencias de secuencia son moderadas y la velocidad es un problema, mientras que los LSTM son los mejores para aplicaciones que requieren memoria detallada y dependencias complejas a largo plazo, aunque con un aumento en las demandas computacionales.
Way forward for Gru en el aprendizaje profundo
Los grus continúan evolucionando como componentes livianos y eficientes en las tuberías modernas de aprendizaje profundo. Una tendencia importante es su integración con las arquitecturas basadas en transformadores, donde
Los grus se usan para codificar patrones temporales locales o servir como módulos de secuencia eficientes en modelos híbridos, especialmente en tareas de voz y sequence temporales.
GRU + ATENCIÓN es otro paradigma en crecimiento. Al combinar los gruses con mecanismos de atención, los modelos obtienen memoria secuencial y la capacidad de centrarse en entradas importantes.
Estos híbridos se utilizan ampliamente en la traducción de la máquina neural, el pronóstico de sequence de tiempo y la detección de anomalías.
En el frente de implementación, los grus son ideales para dispositivos de borde y plataformas móviles debido a su estructura compacta e inferencia rápida. Ya se están utilizando en aplicaciones como reconocimiento de voz en tiempo actual, monitoreo de salud portátil y análisis de IoT.
Los grus también son más susceptibles de cuantización y poda, lo que los convierte en una opción sólida para TinyML e IA incrustada.
Si bien los grus pueden no reemplazar los transformadores en PNL a gran escala, siguen siendo relevantes en entornos que exigen baja latencia, menos parámetros e inteligencia en el dispositivo.
Conclusión
Los grus ofrecen una combinación práctica de velocidad y eficiencia, haciéndolos útiles para tareas como el reconocimiento de voz y la predicción de sequence de tiempo, especialmente cuando los recursos son ajustados.
Los LSTM, aunque más pesados, manejan mejor los patrones a largo plazo y se adaptan a problemas más complejos. Los transformadores están empujando los límites en muchas áreas, pero vienen con mayores costos computacionales. Cada modelo tiene sus fortalezas dependiendo de la tarea.
Mantenerse actualizado sobre la investigación y experimentar con diferentes enfoques, como combinar RNN y mecanismos de atención puede ayudar a encontrar el ajuste correcto. Los programas estructurados que combinan la teoría con aplicaciones de ciencia de datos del mundo actual pueden proporcionar claridad y dirección.
Gran aprendizaje Programa PG en IA y aprendizaje automático es una de esas vías que puede fortalecer su comprensión del aprendizaje profundo y su papel en el modelado de secuencias.